

「ChatGPTなどの生成AIを業務で使ってみたけれど、時々もっともらしい嘘をつかれて困惑した」
「社内の膨大なマニュアルや規定をAIに読み込ませて、正確な回答を自動で生成させたい」
もしあなたがこのような課題を感じているなら、その解決策として「RAG(ラグ)」という技術が注目されています。RAGは、AIが持つ弱点を克服し、より信頼性の高い回答を生成するための革新的なアプローチです。
この記事では、AI技術に関心を持つITエンジニアやDX推進担当者の皆様に向けて、RAGの基本概念から、その具体的な仕組み、ビジネスでの活用事例、そして導入時の注意点までを網羅的に解説します。最後までお読みいただくことで、RAGが自社の課題解決にどう貢献できるのか、明確なイメージを描けるようになるでしょう。
RAG(検索拡張生成)とは?基本概念を解説
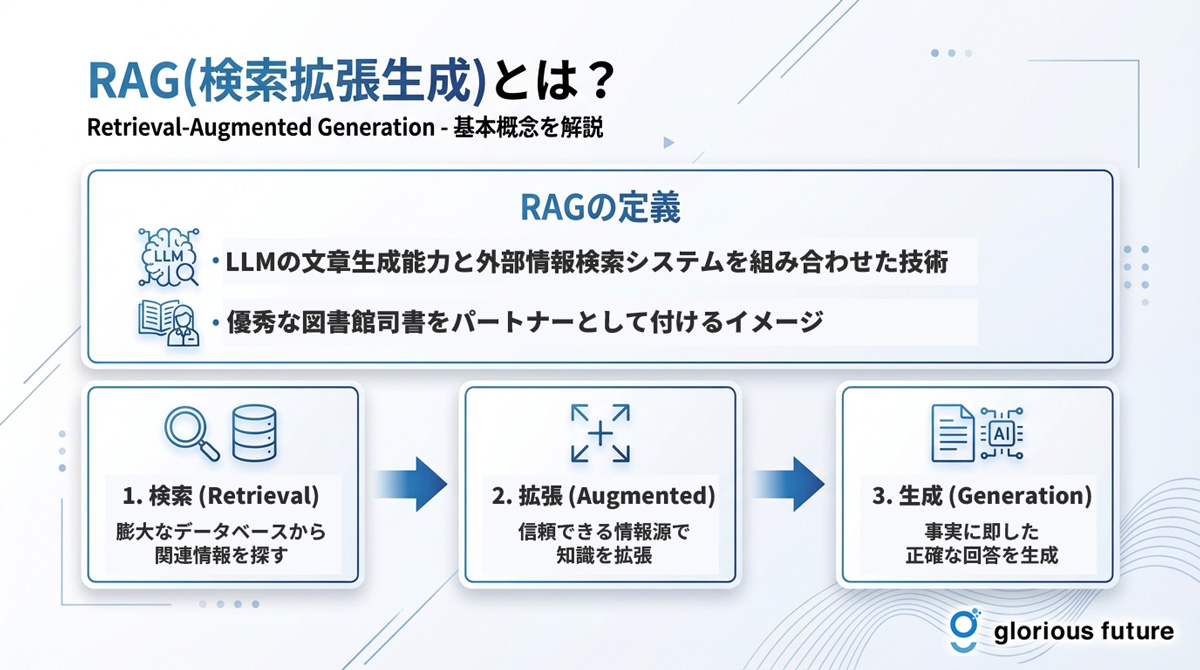
RAG(ラグ)は「Retrieval-Augmented Generation」の略称で、日本語では「検索拡張生成」と訳されます。これは、大規模言語モデル(LLM)が持つ文章生成能力と、外部の情報検索システムを組み合わせた技術です。
身近な例で言えば、LLMに「優秀な図書館司書」をパートナーとして付けるようなものです。質問を受けると、まず司書が膨大なデータベースから関連情報を探し出し、その資料を元にLLMが回答を作成します。これにより、LLMが学習していない最新情報や、社内文書のような限定的な情報に基づいた回答が可能になります。
RAGの定義と全体像
RAGの核心は、LLMが回答を「生成(Generation)」する前に、信頼できる情報源から関連データを「検索(Retrieval)」し、その内容で知識を「拡張(Augmented)」する点にあります。この二段階のプロセスにより、LLM単体で回答を生成する場合に比べて、情報の正確性と信頼性が飛躍的に向上します。つまり、AIが自身の記憶だけに頼るのではなく、事実に基づいた根拠(ファクト)を参照して話すようになるのです。
RAGが注目される背景
ChatGPTをはじめとする生成AIの登場は、多くの業務を効率化する可能性を示しました。しかし同時に、LLMが抱えるいくつかの課題も明らかになりました。
- ハルシネーション(もっともらしい嘘): 事実に基づかない情報を生成してしまうことがある。
- 情報の鮮度: 学習データが古いため、最新の出来事に関する質問には答えられない。
- 専門性・個別性: 社内規定や業界特有の専門用語など、クローズドな情報には対応できない。
RAGは、これらの課題を解決する有効な手段として開発され、AIをより実用的なビジネスツールへと進化させる技術として大きな注目を集めています。
RAGと従来のAI・検索手法の違い
RAGは、従来のLLMや検索エンジンとどう違うのでしょうか。それぞれの特徴を比較してみましょう。
比較項目 | RAG(検索拡張生成) | LLM単体(ChatGPTなど) | 従来の検索エンジン |
主な機能 | 外部情報に基づき、対話形式で回答を生成 | 学習済みデータに基づき、対話形式で回答を生成 | キーワードに合致するWebページを一覧表示 |
情報の鮮度 | ◎ リアルタイムで更新可能 | × 学習時点の情報に依存 | ○ クローリングされた範囲で最新 |
ハルシネーション | △ 抑制できるが発生の可能性は残る | × 発生しやすい | - |
情報源の明示 | ○ 可能 | × 不可能 | ○ 可能 |
社内データ活用 | ○ 可能 | × 不可能(追加学習が必要) | △ 専用エンジンが必要 |
このように、RAGはLLMの自然な対話能力と、検索エンジンの情報収集能力を兼ね備えた、バランスの取れた技術と言えます。
RAGの3つの構成要素(検索・拡張・生成)
RAGという名前は、その仕組みを構成する3つの重要な要素を示しています。
- 検索 (Retrieval): ユーザーの質問に関連する情報を、外部のデータベースから探し出す。
- 拡張 (Augmented): 探し出した情報で、LLMに与える指示(プロンプト)を補強・拡張する。
- 生成 (Generation): 拡張された指示に基づき、LLMが最終的な回答を生成する。
次の章では、この3つの要素がどのように連携して動作するのか、その仕組みをさらに詳しく見ていきましょう。
RAGの仕組み|3つのフェーズを詳しく解説
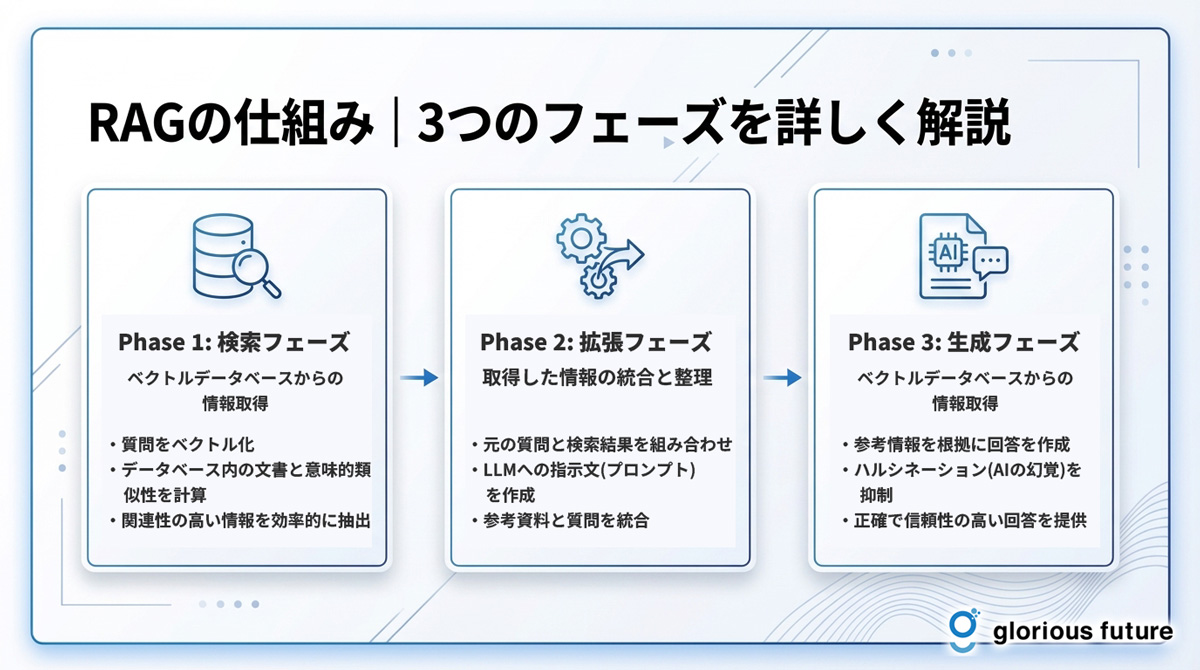
RAGがどのようにして正確な回答を生成するのか、その技術的なプロセスを3つのフェーズに分けて解説します。この流れを理解することで、RAG導入の具体的なイメージが掴みやすくなります。
検索フェーズ:ベクトルデータベースからの情報取得
まず、ユーザーから質問が入力されると、RAGシステムは最初のステップである「検索フェーズ」を開始します。このフェーズの目的は、社内文書やマニュアルなどが格納されたデータベースから、質問内容と関連性の高い情報を見つけ出すことです。
ここでは「ベクトル検索」という技術が重要な役割を果たします。あらかじめデータベース内の文書を「ベクトル」と呼ばれる数値の羅列に変換しておき、ユーザーの質問も同様にベクトル化します。そして、このベクトル同士の距離が近い(=意味的に類似している)文書を、関連情報として効率的に探し出すのです。
拡張フェーズ:取得した情報の統合と整理
次に、検索フェーズで見つけ出した関連情報を、ユーザーが最初に入力した質問と組み合わせる「拡張フェーズ」に移ります。このステップは、LLMに的確な指示を与えるための準備段階と考えることができます。
具体的には、元の質問文と、検索で得られた文書のテキストを統合し、LLMに対する一つのプロンプト(指示文)を作成します。これは、LLMに対して「この参考資料を読んで、以下の質問に答えてください」と具体的な指示を与えるプロセスに似ています。
生成フェーズ:LLMによる回答生成プロセス
最後に、拡張フェーズで作成されたプロンプトがLLMに送られ、最終的な回答を生成する「生成フェーズ」が実行されます。LLMは、与えられた参考情報(コンテキスト)を最優先の根拠として、自然で分かりやすい文章を作成します。
この仕組みにより、LLMは自身の内部知識だけに頼るのではなく、外部から与えられた新鮮で正確な情報に基づいて回答するため、ハルシネーションを大幅に抑制することができます。また、多くのRAGシステムでは、回答と同時に参照した情報源(どの文書のどの部分を参考にしたか)を提示することも可能です。
RAGの処理フロー図解
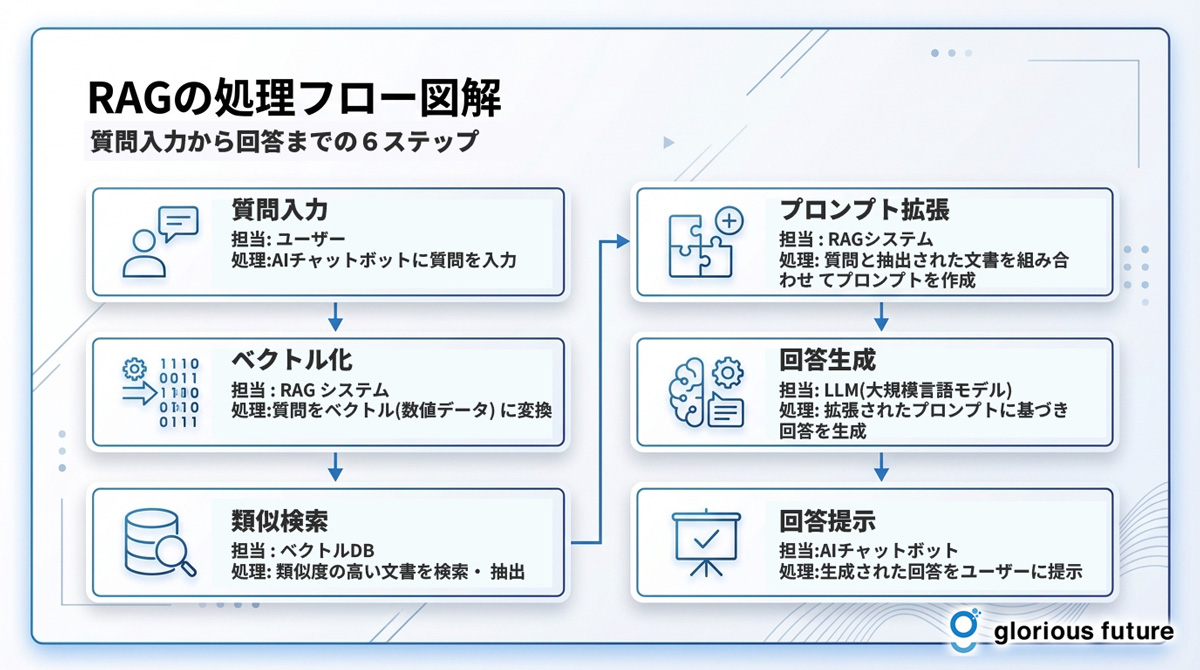
RAGの一連の処理フローをまとめると、以下のようになります。この流れを視覚的に理解することで、各コンポーネントの役割がより明確になります。
ステップ | 担当 | 処理内容 |
1. 質問入力 | ユーザー | AIチャットボットなどに質問を入力する。 |
2. ベクトル化 | RAGシステム | 入力された質問をベクトル(数値データ)に変換する。 |
3. 類似検索 | ベクトルDB | 質問ベクトルと類似度の高い文書ベクトルを検索・抽出する。 |
4. プロンプト拡張 | RAGシステム | 元の質問と抽出した文書を組み合わせ、LLMへのプロンプトを作成する。 |
5. 回答生成 | LLM | 拡張されたプロンプトに基づき、最終的な回答テキストを生成する。 |
6. 回答提示 | RAGシステム | 生成された回答と、根拠となった情報源をユーザーに提示する。 |
RAGのメリット|従来手法と比較した5つの強み
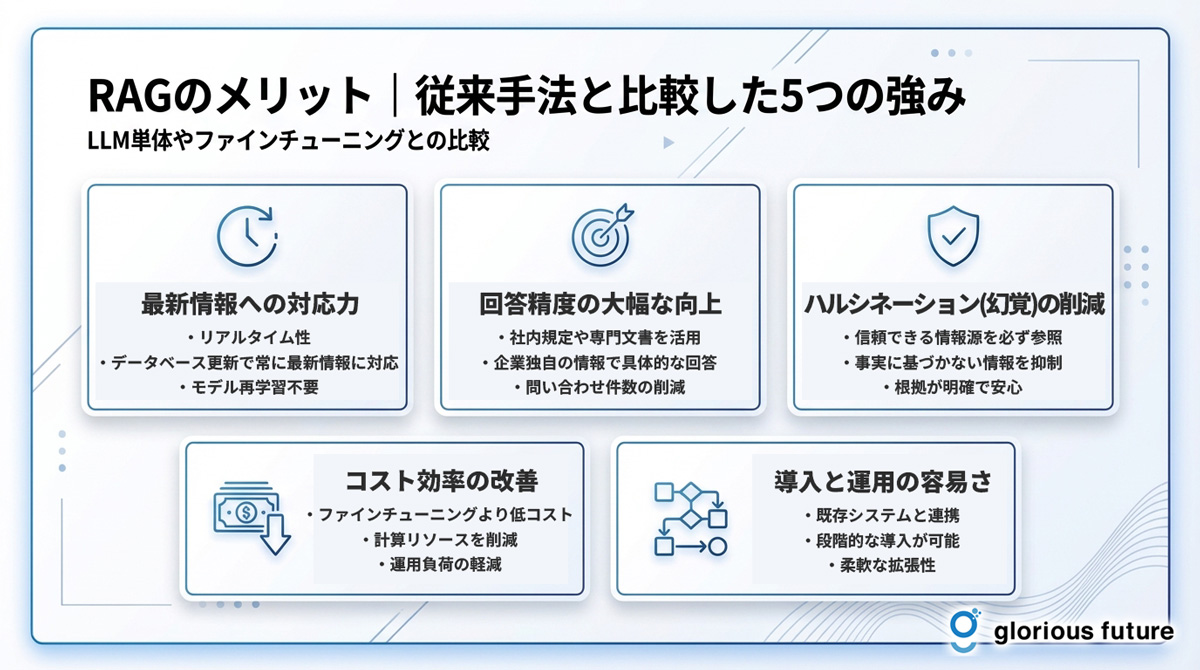
RAGを導入することで、企業は具体的にどのようなメリットを得られるのでしょうか。LLMを単体で利用する場合や、従来のファインチューニングと比較しながら、RAGが持つ5つの強力なメリットを解説します。
最新情報への対応力(リアルタイム性)
LLMの知識は、そのモデルが学習した時点の情報で固定されています。そのため、新しい製品情報や法改正、市場の最新動向などに関する質問には答えることができません。
一方、RAGは外部のデータベースを都度参照します。したがって、データベース側の情報を更新しさえすれば、いつでも最新の情報に基づいた回答を生成できます。このリアルタイム性は、変化の速いビジネス環境において非常に大きな強みとなります。
回答精度の大幅な向上
RAGは、社内規定や専門的な技術文書、顧客からの問い合わせ履歴といった、企業独自のクローズドな情報源を活用できます。これにより、インターネット上の一般的な情報だけでは答えられない、専門的で具体的な質問に対しても、精度の高い回答を提供することが可能になります。従業員の自己解決を促進し、専門部署への問い合わせ件数を削減する効果も期待できます。
ハルシネーション(幻覚)の削減
ハルシネーションは、LLMが事実に基づかない情報を生成してしまう現象で、AI活用の信頼性を損なう大きな要因です。RAGは、回答を生成する際に必ず外部の信頼できる情報源を参照するため、このハルシネーションを大幅に抑制できます。回答の根拠が明確になることで、ユーザーはAIの回答を安心して利用できるようになります。
コスト効率の改善
LLMに特定の知識を学習させる手法として「ファインチューニング」がありますが、これには大量の学習データと高い計算コスト、そして専門的な技術が必要です。RAGは、ファインチューニングに比べて比較的低コストで導入・運用が可能です。特に、情報の更新が頻繁に必要な場合、モデル全体を再学習させる必要がないため、運用コストを大きく抑えることができます。
カスタマイズ性の高さ
RAGシステムは、その構成要素(検索エンジン、ベクトルデータベース、LLM)を柔軟に組み合わせたり、入れ替えたりすることが可能です。例えば、検索精度を向上させるために検索アルゴリズムをチューニングしたり、特定のタスクに特化したLLMを選択したりと、企業の要件に合わせてシステムを最適化できます。このカスタマイズ性の高さが、多様なビジネスニーズへの対応を可能にします。
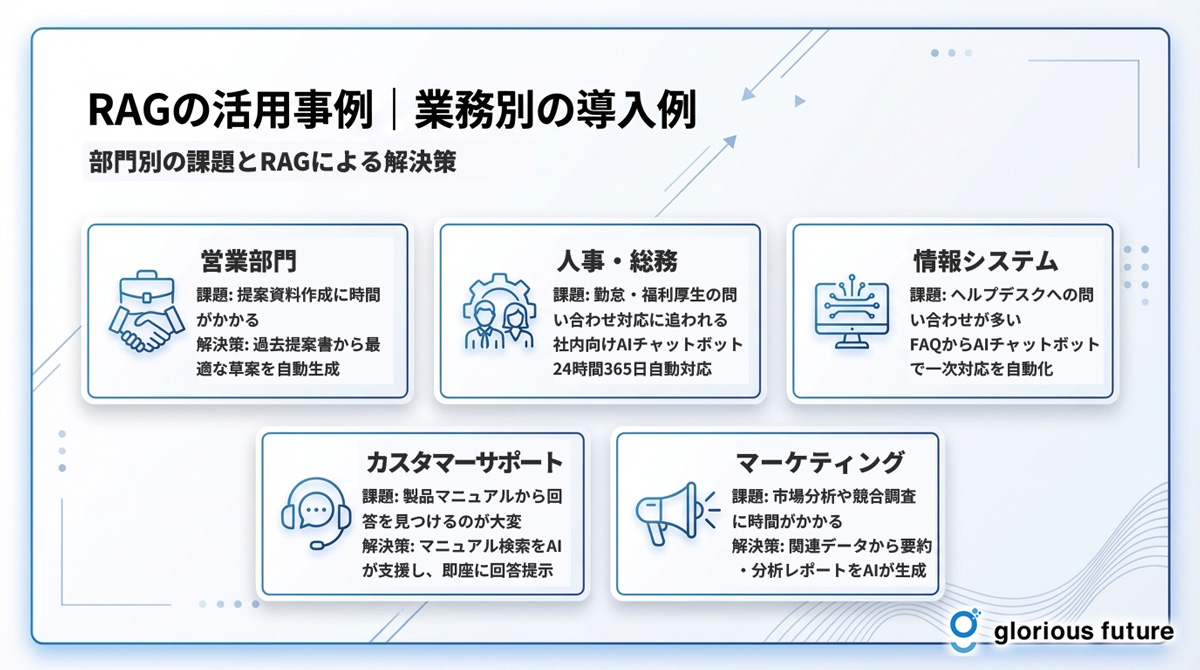
RAGの活用事例|業務別の導入例
RAGは、その特性を活かして既にさまざまな業務で活用されています。ここでは、具体的な部門や業務シーンを想定し、RAGがどのように課題解決に貢献できるのかを見ていきましょう。
部門・業務 | 課題 | RAGによる解決策・活用例 |
営業部門 | 顧客提案資料の作成に時間がかかる。過去の類似案件や成功事例を探すのが大変。 | 過去の提案書や製品資料をデータベース化。顧客の課題を入力するだけで、最適な提案書の草案や関連資料を自動生成する。 |
人事・総務 | 社員からの勤怠や福利厚生に関する問い合わせ対応に追われている。 | 就業規則や各種申請マニュアルを情報源とする社内向けAIチャットボットを構築。社員の質問に24時間365日自動で回答する。 |
情報システム | ヘルプデスクへのPC操作やシステムトラブルに関する問い合わせが多い。 | FAQやトラブルシューティングマニュアルを学習させたAIチャットボットを導入。一次対応を自動化し、担当者の負担を軽減する。 |
カスタマーサポート | 膨大な製品マニュアルから顧客の質問に合う回答を探すのに時間がかかる。 | 製品マニュアルや過去の問い合わせ履歴をRAGで検索。顧客の問い合わせ内容に応じて、最適な回答と参照すべきマニュアルの箇所を提示する。 |
マーケティング | 競合製品の調査や市場トレンドのレポート作成に工数がかかる。 | ニュースリリースや調査レポートを定期的に収集するデータベースを構築。特定のテーマに関する市場動向を要約・レポート化する。 |
このように、RAGは特定の部門に限らず、社内のナレッジ活用や問い合わせ対応業務全般の効率化・高度化に貢献するポテンシャルを秘めています。
営業部門×RAG:提案活動の効率化
営業担当者は、顧客ごとに最適な提案書を作成するために多くの時間を費やしています。RAGを活用すれば、過去の成功事例や製品の技術資料、価格表などを情報源として、顧客の業種や課題に合わせた提案書のドラフトを瞬時に作成できます。これにより、営業担当者は資料作成の時間を削減し、より戦略的な顧客との対話に集中できるようになります。
人事・総務部門×RAG:バックオフィス業務の効率化
人事・総務部門には、社員から就業規則や経費精算、福利厚生に関する同様の質問が繰り返し寄せられます。これらの規定やマニュアルをRAGの情報源とすることで、24時間対応可能な社内向けAIチャットボットを構築できます。社員はいつでも気軽に質問でき、自己解決率が向上するため、バックオフィス部門の業務負荷を大幅に軽減できます。
情報システム部門×RAG:IT運用の高度化
情報システム部門のヘルプデスクは、パスワードのリセットやソフトウェアのインストール方法など、定型的な問い合わせに多くの時間を割かれています。FAQや操作マニュアルをRAGシステムに連携させることで、これらの一次対応をAIに任せることができます。担当者はより専門的なインフラ運用やセキュリティ対策といった、付加価値の高い業務にリソースを集中させることが可能になります。
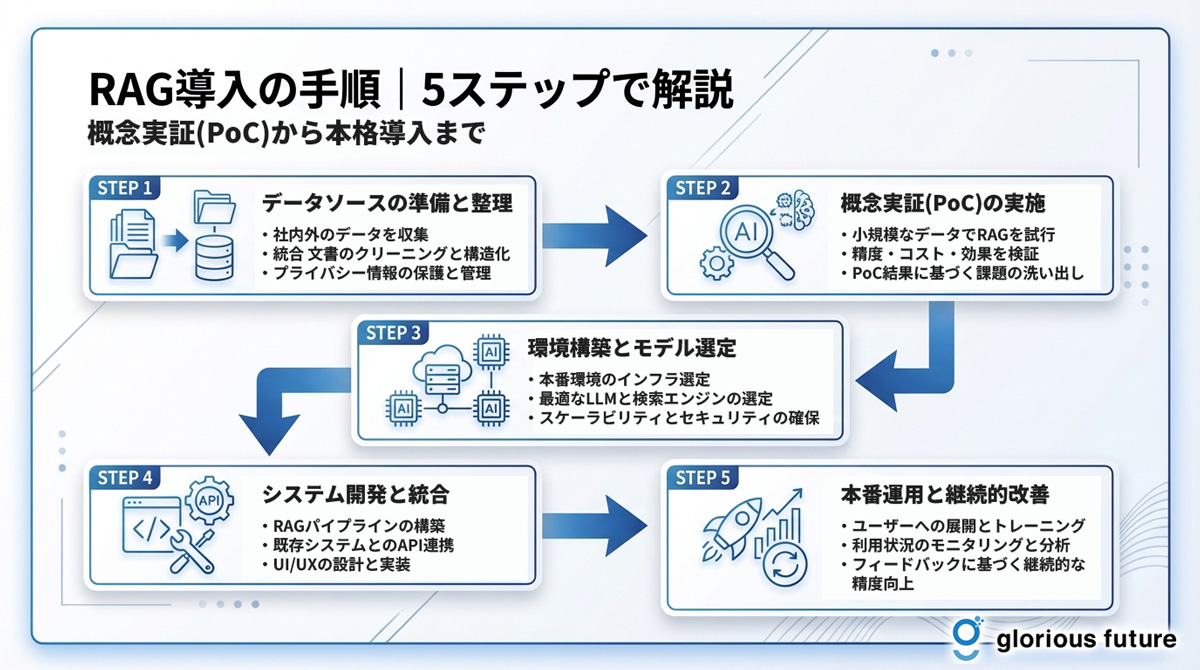
RAG導入の手順|5ステップで解説
RAGを自社で導入し、概念実証(PoC)を進めるには、どのような手順を踏めばよいのでしょうか。ここでは、RAGシステムを構築するための基本的な5つのステップを解説します。
ステップ1:データソースの準備と整理
RAGの回答品質は、情報源となるデータの品質に大きく依存します。まずは、社内ファイルサーバーやデータベースに散在している文書の中から、RAGに読み込ませる対象を選定します。古い情報や誤った記述が含まれている場合は、事前にクリーニングや整理を行うことが重要です。
ステップ2:ベクトルデータベースの構築
次に、準備した文書データを検索可能な状態にするため、ベクトルデータベースを構築します。文書を意味のある単位(チャンク)に分割し、それぞれのチャンクを埋め込みモデルによってベクトル化します。このベクトルデータを格納し、高速な類似検索を可能にするのがベクトルデータベースの役割です。
ステップ3:埋め込みモデルの選定
文書や質問をベクトルに変換する「埋め込みモデル」の選定は、検索精度を左右する重要な要素です。日本語に特化したモデルや、特定の業界用語に対応したモデルなど、様々な選択肢があります。自社のデータソースの特性や目的に合わせて、最適なモデルを選定する必要があります。
ステップ4:生成モデル(LLM)の統合
検索システムと連携させる生成モデル(LLM)を選び、APIなどを通じて統合します。OpenAIのGPTシリーズやGoogleのGemini、AnthropicのClaudeなど、それぞれに特徴を持つLLMが存在します。回答の品質、コスト、処理速度などを考慮して、自社のユースケースに最も適したモデルを選択します。
ステップ5:テストと精度向上の施策
システムが完成したら、想定される質問を入力してテストを行い、回答の精度を評価します。期待通りの回答が得られない場合は、データの分割方法(チャンキング)を見直したり、プロンプトを調整したりと、継続的なチューニングが必要になります。この改善サイクルを回すことが、RAGシステムの価値を高める鍵となります。
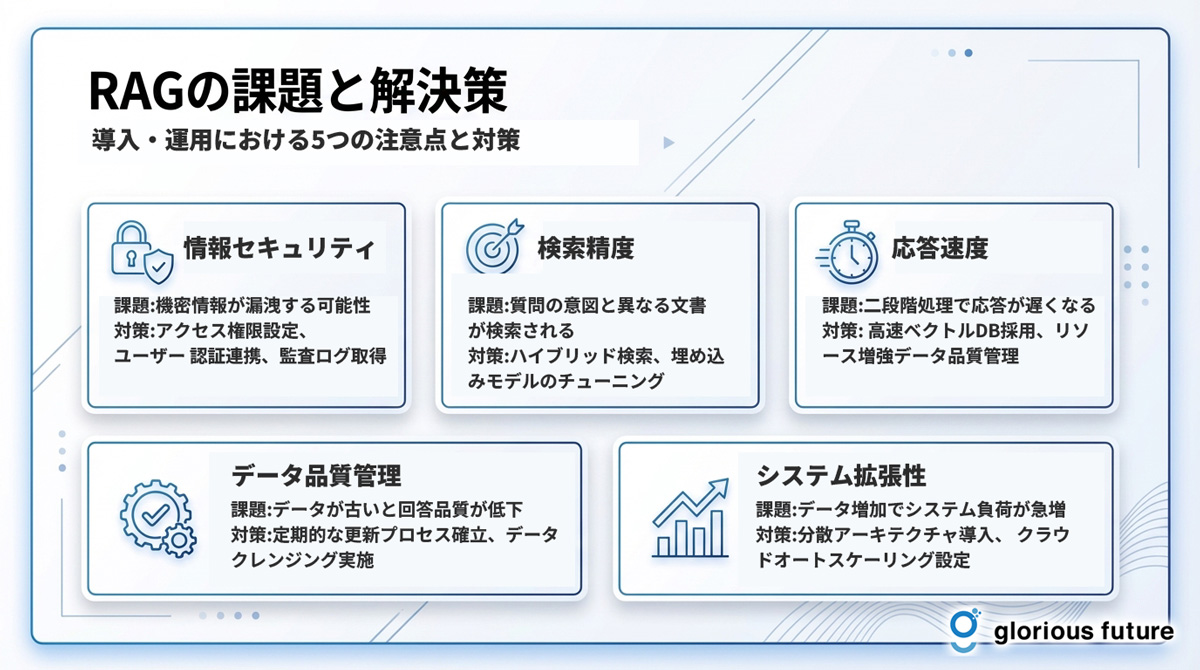
RAGの課題と解決策
RAGは非常に強力な技術ですが、導入や運用にあたってはいくつかの課題や注意点が存在します。事前にこれらのリスクを理解し、適切な対策を講じることが、プロジェクトを成功に導くために不可欠です。
課題・リスク | 具体的な内容 | 解決策・対策 |
情報セキュリティ | 権限のないユーザーに機密情報が漏洩する可能性がある。 | データソースへの厳格なアクセス権限設定。ユーザー認証との連携。監査ログの取得。 |
検索精度 | 質問の意図と異なる文書が検索され、不正確な回答が生成される。 | 埋め込みモデルのチューニング。キーワード検索とベクトル検索の併用(ハイブリッド検索)。データの前処理(ノイズ除去)。 |
応答速度 | 検索と生成の二段階処理のため、LLM単体より応答が遅くなる場合がある。 | 高速なベクトルデータベースの採用。検索対象データの最適化。ハードウェアリソースの増強。 |
データ品質管理 | 情報源のデータが古い、または不正確だと、回答の品質も低下する。 | 定期的なデータソースの棚卸しと更新プロセスの確立。データオーナーの明確化。 |
コスト管理 | LLMのAPI利用料や、データベースの運用コストが発生する。 | 利用頻度の低い時間帯はリソースを縮小。より安価なLLMモデルの検討。キャッシュ機能の活用。 |
情報セキュリティとプライバシー保護
RAGは社内の機密情報にアクセスする可能性があるため、セキュリティ対策は最重要課題です。データベースにアクセスするユーザーの権限を厳格に管理し、役職や部署に応じて閲覧できる情報の範囲を制御する必要があります。誰が、いつ、どの情報にアクセスしたかを記録する監査ログの仕組みも、不正利用を防ぐ上で重要です。
検索精度の維持・向上策
RAGの性能は検索精度に大きく依存します。検索精度が低いと、見当違いの情報を基に回答が生成され、結果的にハルシネーションを引き起こします。精度を向上させるには、データの前処理を丁寧に行い、文書の分割方法を工夫したり、複数の検索手法を組み合わせるハイブリッド検索を導入したりといった継続的な改善活動が求められます。
応答速度の最適化手法
RAGは検索と生成という2つのステップを踏むため、LLM単体よりも応答に時間がかかる傾向があります。ユーザー体験を損なわないためには、応答速度の最適化が必要です。
処理能力の高いベクトルデータベースを選定したり、検索インデックスのサイズを最適化したりすることで、遅延を改善することができます。
データ品質管理の重要性
「Garbage In, Garbage Out(ゴミを入れれば、ゴミしか出てこない)」という言葉の通り、RAGの回答品質は参照するデータの品質に直結します。情報源となる文書の正確性や最新性を維持するための運用プロセスを確立することが不可欠です。各データに対する責任部署(データオーナー)を定め、定期的なレビューと更新を行う体制を整えましょう。
コスト管理のポイント
RAGの運用には、LLMのAPI利用料やベクトルデータベースのサーバー費用など、継続的なコストが発生します。利用状況をモニタリングし、費用対効果を定期的に評価することが重要です。例えば、性能要件を満たす範囲でより安価なLLMモデルに切り替えたり、一度検索した結果を一時的に保存(キャッシュ)してAPI呼び出し回数を減らしたりといった工夫で、コストを最適化できます。
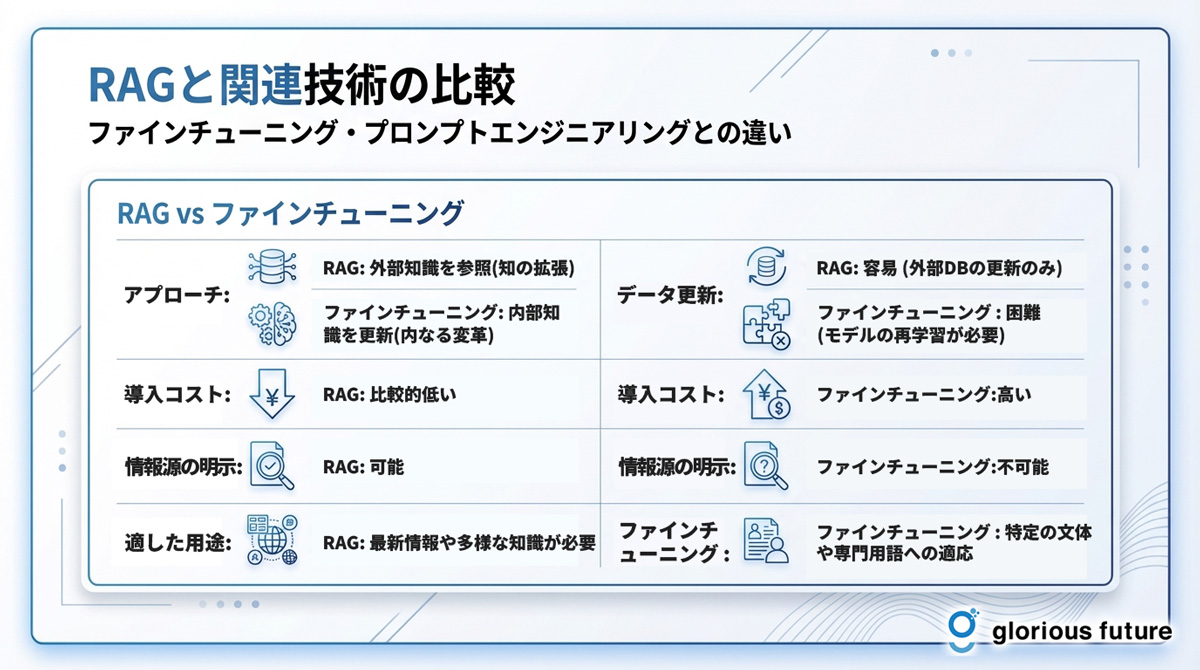
RAGと関連技術の比較
RAGの理解をさらに深めるために、混同されがちな他のAI関連技術との違いを明確にしておきましょう。それぞれの技術の特性を理解することで、課題に対して最適なアプローチを選択できるようになります。
ファインチューニングとの違い
ファインチューニングは、特定のデータセットを使ってLLMの内部パラメータ自体を調整し、モデルを「再教育」するような手法です。一方、RAGはモデル自体には手を加えず、外部から「参考書」を与えるようなアプローチです。
比較項目 | RAG(検索拡張生成) | ファインチューニング |
アプローチ | 外部知識を参照(知の拡張) | 内部知識を更新(内なる変革) |
データ更新 | 容易(外部DBの更新のみ) | 困難(モデルの再学習が必要) |
導入コスト | 比較的低い | 高い |
情報源の明示 | 可能 | 不可能 |
適した用途 | 最新情報や多様な知識が必要なタスク | 特定の文体や専門用語への適応 |
どちらか一方が優れているわけではなく、目的に応じて使い分ける、あるいは両者を組み合わせることが重要です。
プロンプトエンジニアリングとの使い分け
プロンプトエンジニアリングは、LLMから望ましい回答を引き出すために、入力する指示(プロンプト)を工夫する技術です。RAGのプロセス内でも、検索結果をLLMに渡す際に効果的なプロンプトエンジニアリングが活用されます。RAGが「何を参考にするか」という仕組みを提供するのに対し、プロンプトエンジニアリングは「どのように伝えるか」という技術であり、両者は互いに補完し合う関係にあります。
ハイブリッドアプローチの可能性
RAGとファインチューニングは、組み合わせて利用することも可能です。例えば、まず業界特有の専門用語や文体をファインチューニングでLLMに学習させ、その上でRAGを使って最新の製品情報を参照させる、といったハイブリッドなアプローチが考えられます。これにより、それぞれの技術の長所を活かし、より高度で専門的なAI応答システムを構築することができます。
RAG技術の今後の展開
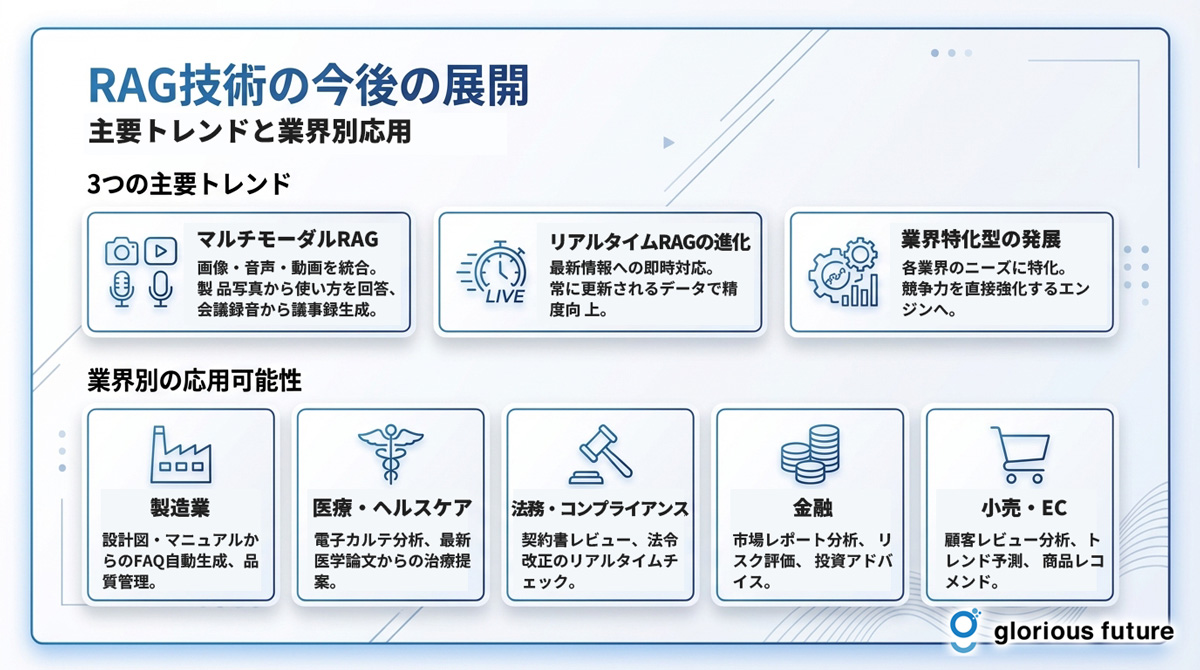
RAGは現在も活発に研究開発が進められている分野であり、その可能性はさらに広がりを見せています。2025年以降、RAG技術はより高度化し、企業のビジネス活動に不可欠な基盤技術となっていくことが予測されています。ここでは、特に注目すべき今後のトレンドをいくつか紹介します。
マルチモーダルRAG(画像・音声対応)
現在のRAGは主にテキストデータを扱いますが、将来的には画像、音声、動画といった多様な形式のデータを統合的に扱える「マルチモーダルRAG」が主流になると予測されています。例えば、製品の写真を見せて「この商品の使い方は?」と質問すると、画像を認識した上で関連マニュアルから情報を検索し回答します。会議の録音データから議事録を自動生成したり、研修動画から必要なシーンを検索したりと、応用範囲が大きく広がることが期待されています。
リアルタイムRAGの進化
RAG技術は各業界の専門的なニーズに特化したソリューションとしても発展していきます。金融業界では市場分析レポートの自動生成やコンプライアンスチェック、医療分野では最新論文に基づいた診断支援、法曹界では判例検索システムの高度化、不動産業界では物件の自動査定、教育分野では個別学習支援など、各業界特有のデータと組み合わせることで、RAGは企業の競争力を直接強化するエンジンとなり得ます。今後、業界別に特化したRAGサービスが次々と生まれることが予想されます。
業界別の応用可能性
RAG技術は各業界の専門的なニーズに特化したソリューションとしても発展していきます。業界特有のデータと組み合わせることで、RAGは企業の競争力を直接強化するエンジンとなり得ます。
主な活用例は以下の通りです。
- 金融業界 : 市場分析レポートの自動生成、投資判断の支援、コンプライアンスチェックの自動化
- 医療分野 : 最新論文に基づいた診断支援、類似症例の検索、治療法の提案
- 法曹界 : 判例検索システムの高度化、法律条文の即時照会、訴訟準備の効率化
- 不動産業界: 物件の自動査定、顧客ニーズに合わせた物件提案、市場動向分析
- 教育分野 : 個別学習支援、学習者に最適な教材の提示、理解度に応じた説明生成
今後、各業界でRAGを活用した独自のサービスやプロダクトが次々と生まれることが予想されます。
RAGに関するよくある質問(FAQ)
最後に、RAGの導入を検討する際によく寄せられる質問とその回答をまとめました。
RAG導入のコストは?
RAGの導入コストは、システムの規模や使用する技術によって大きく変動します。主な内訳は、クラウドサービスの利用料(ベクトルデータベース、LLMのAPIなど)、開発に関わる人件費、そして継続的な運用保守費用です。小規模なPoC(概念実証)であれば比較的低コストで始められますが、全社規模での展開には相応の投資が必要となります。
どんな企業に向いている?
以下のような特徴を持つ企業は、RAG導入によるメリットを特に大きく享受できると考えられます。
- 社内にマニュアル、規定、FAQなどのナレッジが豊富に蓄積されている企業
- 従業員や顧客からの問い合わせ対応に多くのリソースを割いている企業
- 最新の情報を迅速に業務に反映させる必要がある企業
- AIを活用して業務効率化や新たな付加価値創出を目指す企業
導入期間の目安は?
導入期間もプロジェクトの要件によって様々です。対象とするデータソースが限定的で、目的が明確なPoCであれば、数週間から数ヶ月でプロトタイプを構築することも可能です。しかし、複数のシステムと連携する大規模な導入の場合は、要件定義から設計、開発、テストを含めて半年以上の期間が必要になることもあります。
必要な技術スキルは?
RAGシステムを自社で構築・運用するには、以下のような技術スキルを持つ人材が必要となります。
- Pythonなどのプログラミング言語
- LLMや各種APIに関する知識
- クラウドインフラ(AWS, Google Cloudなど)の構築・運用スキル
- データの前処理や品質管理に関する知識
- ベクトルデータベースに関する理解
これらのスキルを持つ人材が社内にいない場合は、専門知識を持つ外部パートナーとの協業が有効な選択肢となります。
RAG導入で実現できること|まとめ

本記事では、生成AIの新たな可能性を切り拓くRAGについて、その基本概念から仕組み、メリット、導入方法までを網羅的に解説しました。
最後に、この記事の重要なポイントを振り返ります。
RAGの重要ポイントの再確認
- RAGとは : 検索拡張生成の略。LLMに外部のデータベースを検索させ、その情報に基づいて回答を生成させる技術。
- 主なメリット: ハルシネーションの抑制、最新情報への対応、社内データ活用、コスト効率の改善。
- 仕組み : 「検索」「拡張」「生成」の3つのフェーズで構成され、ベクトル検索が重要な役割を果たす。
- 課題 : データ品質、セキュリティ、検索精度などが成功の鍵となり、継続的な運用管理が不可欠。
導入検討時のチェックリスト
自社でRAGの導入を検討する際には、以下の項目をチェックリストとしてご活用ください。
チェック項目 | 確認内容 |
① 目的の明確化 | RAGを導入して、どのような業務課題を解決したいか?(例:問い合わせ対応の効率化、資料作成時間の短縮) |
② 対象データの有無 | RAGの情報源として活用できる、整理された社内データ(マニュアル、FAQ等)は存在するか? |
③ 体制の確認 | プロジェクトを推進する担当者や、開発・運用に必要なスキルを持つ人材はいるか? |
④ 費用対効果の試算 | 導入・運用コストに見合うだけの業務効率化やコスト削減効果が見込めるか? |
⑤ スモールスタート計画 | まずは特定の部署や業務に限定して、PoC(概念実証)から始める計画は立てられているか? |