

AI技術を検索に活用するケースが増えてきたものの、「AIの回答は本当に正しい情報?」「情報は最新?」など、不安を抱く方も少なくありません。AIの正確性や信頼性は、「RAG(検索拡張生成)」技術の進歩に伴い上昇しています。
今回は、RAGの概要や生成AIとの連携、導入メリット、ファインチューニング(事前に学習したモデルを対象に、追加の学習を行うプロセス)との違いを解説します。
RAGとは?【より正確な回答を生成する仕組みのこと】
RAG(検索拡張生成)とは、大規模言語モデル(LLM)に自社の保有情報や外部のデータを取り込み、それらを活用して正確な回答を生成する仕組みです。
RAGと生成AIを活用することで、社内情報や論文など、未学習のデータからもより正確な回答を生成できます。この技術は、生成AIの弱点である正確性・最新性を補う仕組みとして、注目を集めています。
生成AIとの関係:精度と信頼度を向上できる
従来の生成AIは、学習済みのデータに基づいているので、情報が古くなる課題がありました。しかし、RAGは外部情報を取り込んで検索できるので、最新の基準の回答が可能です。そのため、誤った推論やバイアス(偏った情報)が減少し、生成AIの精度と信頼性が向上します。
企業の問い合わせシステムやカスタマーサポートのチャットボットなどにRAGを導入すれば、トラブルシューティング情報を高い精度で回答でき、顧客満足度の向上に役立てられます。
RAGの仕組み
RAGは大きく「検索フェーズ」と「生成フェーズ」の2段階で構成されています。ここからは、RAGの仕組みを各フェーズに分けて解説します。
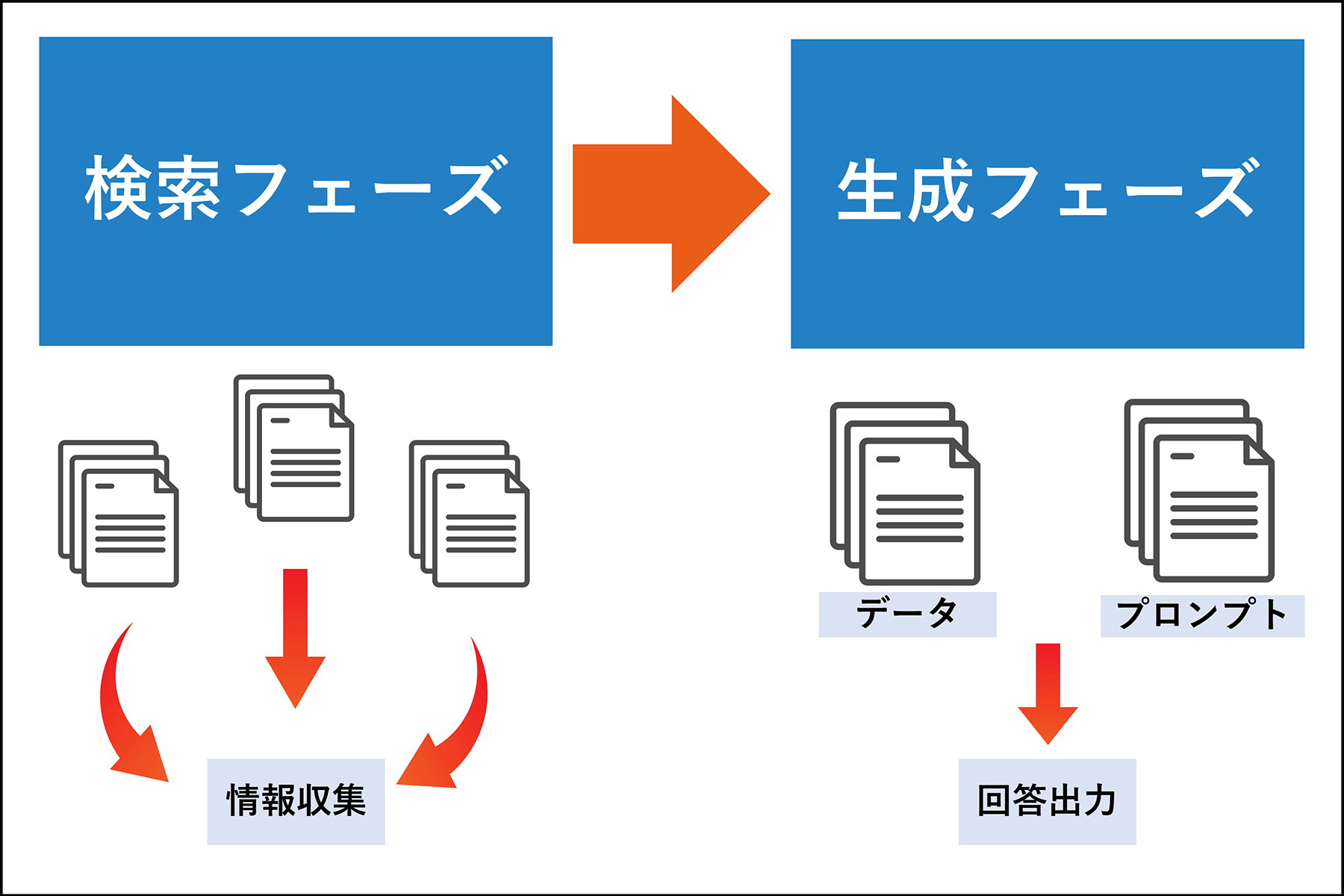
検索フェーズ:情報を外部データから検索
検索フェーズでは、ユーザーが入力したテキストを数値ベクトルに変換します。数値ベクトルとは、入力データを数値の配列に変換して、文脈や意味の類似性を計算できるようにすることです。
数値ベクトルを用いて、インターネット上にある最新ニュースや企業の文書、各種データベースなどから検索します。多数の情報から関連性の高いものを数件抽出し、生成フェーズへの入力データとして活用することで、鮮度が高く高精度な情報を取り入れられます。
生成フェーズ:検索結果をLLM(大規模言語モデル)に反映
検索フェーズで取得した情報は、生成フェーズでLLM(大規模言語モデル)に取り込まれます。抽出した情報をプロンプト(AIへの指示文章)に組み込み、LLMが収集データ・プロンプトを踏まえて回答を生成します。
また、生成フェーズでは、どの情報をどのように活用するかを判断するアルゴリズムが組み込まれており、不要な情報を排除する設計となっています。
RAGをAIに導入するメリット
RAGをAIに導入することで、主に以下のメリットが得られます。
ここからは、RAGをAIに導入するメリットを1つずつ解説します。
最新情報を常に反映できる
RAGをAIに導入すると、ニュース速報や株価情報、天気予報など、更新率が高い情報に素早く対応でき、回答の信頼性も向上します。
また、企業の内部情報と外部情報を組み合わせることで、経営判断やマーケティング戦略に活かせます。これにより、ハルシネーション(AIが事実と異なる回答を生成すること)のリスクを大幅に軽減し、ユーザーは常に信頼性の高い回答を得られます。
LLMの追加学習不要でコスト削減
従来、AIの回答精度を向上させるには追加学習が必要でしたが、RAGは外部検索で最新情報を補完するので、LLM自体の追加学習が不要です。学習の時間を削減できる分、学習コストやリソースを大幅に節約できます。
社内システムや業務システムと連携可能
RAGは企業内の書類やデータベース、業務データなどを取り込み、外部情報と統合して回答を生成することで、業務効率の向上と情報の一元管理ができます。社内のナレッジ管理システムや過去の問い合わせ履歴などが管理しやすくなり社員の疑問解決や意思決定に活用できます。
RAGとファインチューニングとの違い
RAGと比較されやすい技術として、ファインチューニングが挙げられます。RAGとファインチューニングは、生成AIの精度向上を目指す技術ですが、仕組みが異なります。ここからは、RAGとファインチューニングとの違いを解説します。
ファインチューニングの仕組み
ファインチューニングとは、事前学習済みのAIモデルに追加学習を行うことで、特定の分野や用途に合わせて最適化する手法です。ファインチューニングによりAIモデルに専門知識が蓄積され、特定の分野で高精度な回答ができるようになります。
しかし、RAGと比較すると、ファインチューニングの追加学習には時間とコストがかかる点がデメリットです。
どっちを導入すべき?比較ポイント
RAGとファインチューニングは、利用目的や必要な情報の更新頻度に応じて適切に選択することが重要です。
例えば、ニュースや最新情報を把握したい場合や自社に社内検索エンジンがある場合は、リアルタイム検索の活用やコスト削減、短期間で導入できるRAGが向いています。
一方、特定分野に特化した知識が求められる場合は、専門知識を蓄積するファインチューニングが効果的です。
| RAG | ファインチューニング |
|---|---|---|
学習方法 | 外部情報からのデータ習得を適用 | 事前データ・教師あり学習を適用 |
メリット | 最新情報に基づいて出力可能 | 特定分野への理解を深めて出力可能 |
デメリット | 情報の正確が収集する外部データに左右される | 学習には前もってデータの準備が必要 |
RAGを社内AIに取り入れる際のポイント
RAGを効果的に社内AIシステムへ組み込むためには、いくつかのポイントを押さえておく必要があります。ここからは、重視すべき2つのポイントを解説します。
高精度の検索エンジンを使用する
RAGの性能は、採用する検索エンジンの精度に関係します。検索エンジンのアルゴリズムによっては、誤った回答が生成される可能性があります。そのため、高精度の検索エンジンを使用して、求めている情報を回答させることが重要です。
また、検索エンジンにはキーワード検索だけでなく、文脈や類似度を考慮したセマンティック検索(検索文の意図に合った検索結果を提供する技術)などの機能が欠かせません。
さらに、アクセス権管理や各種ファイル形式などに対応できるシステムを導入することで、より正確な回答を抽出できます。
機密情報を扱う際のセキュリティを確保する
企業内で機密情報を扱う場合、情報漏洩などのリスクを抑えるためのセキュリティ対策が必要です。
社内に限定した検索システムを構築し、外部への情報流出を防止できる仕組みが必要です。さらに、個人情報や機密データを取り扱う際は、暗号化や閲覧権限の割り当てなどのセキュリティ対策も推奨されます。
暗号化や閲覧権限の割り当てが不十分の場合、社内の機密データが全社員向けの回答として生成され、情報漏洩につながるリスクが高まります。セキュリティリスクを減らすには、閲覧権限の設定に注意が必要です。
まとめ
今回は、RAGの基本的な概念や仕組み、導入するメリット、ファインチューニングとの違い、社内AIに取り入れる際のポイントなどを解説しました。RAGは、LLMに外部データを取り込み、より正確な回答を生成する技術です。
RAGの主なメリットは、最新情報を常に反映できることやLLMの追加学習が不要なこと、社内システムとの連携が可能なことが挙げられます。
また、RAG導入時には高精度な検索エンジンの使用と、機密情報を扱う際のセキュリティ確保が重要なポイントです。最新の技術動向や導入のポイントを押さえることで、より信頼性の高いAIシステムを構築できるでしょう。