

データベースの活用は、企業の意思決定や業務効率化に大きな影響を与えます。特に、顧客データや売上情報の分析において、重複したレコードが含まれていると適切な判断が難しくなる場合があります。このような問題に対しては、SQLのDISTINCTコマンドが役立ちます。
そこで本記事では、重複データの削除にお悩みの方やDISTINCTの基本的な使い方を知りたい方に向けて、SQLの重複削除方法であるDISTINCTの使い方やDELETEの使い方、DISTINCTを使う際の注意点、GROUP BYの違いなどについて解説します。
SQLについて、概要から詳しく知りたい方、使い方の基本をおさらいしたい方は、
「SQLとは?データベース言語の基礎知識・重要性を解説」をご覧ください。
SQLの重複削除方法【DISTINCTの使い方】
データベース操作でよく活用されるDISTINCTコマンドは、重複したデータを整理できる便利な機能です。SELECT文に組み合わせると、データベースから抽出した情報から同じ値を省いた結果が得られます。
SQLのSELECT文は、情報を取り出す基本的な命令になりますが、DISTINCTを付け加えることで、一意なデータ(重複がない状態のデータ)にまとめられます。特にデータ分析やレポート作成の場面で役立つ実用的なSQLコマンドと言えます。
書式は「SELECT DISTINCT カラム名[,カラム名...] FROM テーブル名;」
SQLのDISTINCTは「SELECT DISTINCT カラム名[,カラム名...] FROM テーブル名;」という形式で記載します。実際のデータ抽出では、SELECTコマンドで指定した列から一意な値のみが選ばれます。
DISTINCTを活用すると、データベース内の同じ値を含む行が自動的に取り除かれ、異なる値だけがまとめられます。このDISTINCTコマンドにより、データ管理者は必要な情報を効率的に選び出せます。
テーブルを作成してクエリを実行する
DISTINCT を使用して重複データを削除するには、まずサンプルデータを作成します。手順は以下の通りです。
CREATE TABLE member (
member_id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
address VARCHAR(50) NOT NULL,
department VARCHAR(20) NOT NULL,
PRIMARY KEY (member_id)
);2.次にdepartment列に重複があるデータを追加
INSERT INTO member (name, address, department) VALUES
('山田太郎','東京都新宿区','総務部'),
('鈴木花子','大阪府大阪市','経理部'),
('佐藤次郎','愛知県名古屋市','総務部'),
('高橋美咲','北海道札幌市','マーケティング部'),
('田中一郎','福岡県福岡市','経理部'),
('斉藤健','神奈川県横浜市','IT部');3.データを確認
SELECT * FROM member;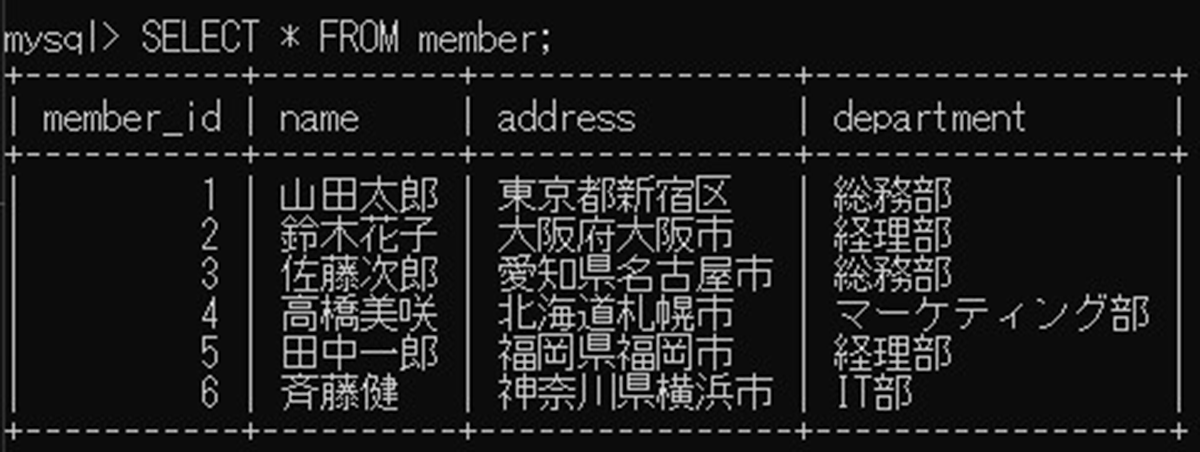
「memberテーブル」には次のようなデータが入っています。部署コード「department」の列で重複があります。
member_id | name | address | department |
1 | 山田太郎 | 東京都新宿区 | 総務部 |
2 | 鈴木花子 | 大阪府大阪市 | 経理部 |
3 | 佐藤次郎 | 愛知県名古屋市 | 総務部 |
4 | 高橋美咲 | 北海道札幌市 | マーケティング部 |
5 | 田中一郎 | 福岡県福岡市 | 経理部 |
6 | 斉藤健 | 神奈川県横浜市 | IT部 |
4.部署コード「department」の重複を削除する場合は以下のSQL文を使用
SELECT DISTINCT department FROM member;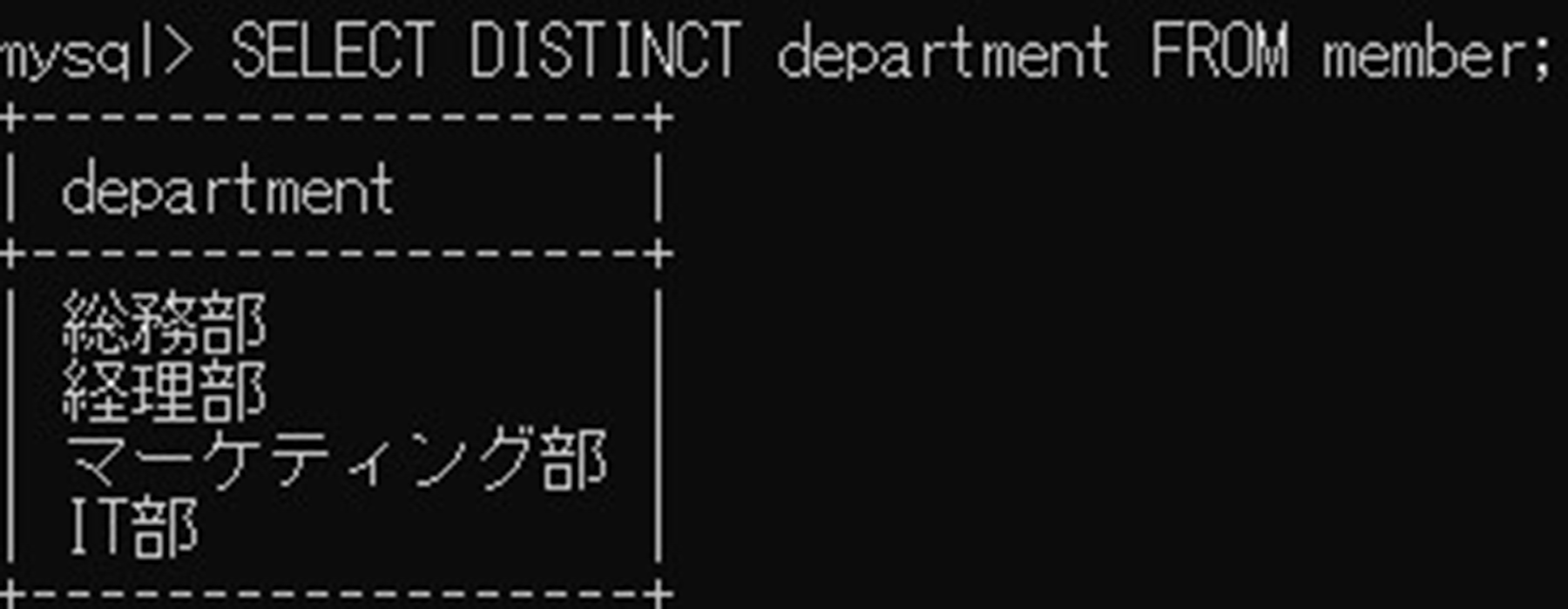
DISTINCTを使うことで、重複した列をひとつにまとめることができました。
複数列の重複を削除も可能
DISTINCTは複数の列(カラム)にも適用できます。以下では、複数の列にDISTINCTを適用する方法について解説します。
1.サンプル用のテーブルの作成
CREATE TABLE member (
member_id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
address VARCHAR(50) NOT NULL,
department VARCHAR(20) NOT NULL,
PRIMARY KEY (member_id)
);2.次にaddressとdepartment列に重複があるデータを追加
INSERT INTO member (name, address, department) VALUES
('山田太郎' ,'東京都新宿区' ,'総務部'),
('鈴木花子' ,'大阪府大阪市' ,'経理部'),
('佐藤次郎' ,'東京都新宿区' ,'総務部'),
('高橋美咲' ,'北海道札幌市' ,'マーケティング部'),
('田中一郎' ,'大阪府大阪市' ,'経理部'),
('斉藤健' ,'東京都新宿区' ,'総務部');3.データを確認
SELECT * FROM member;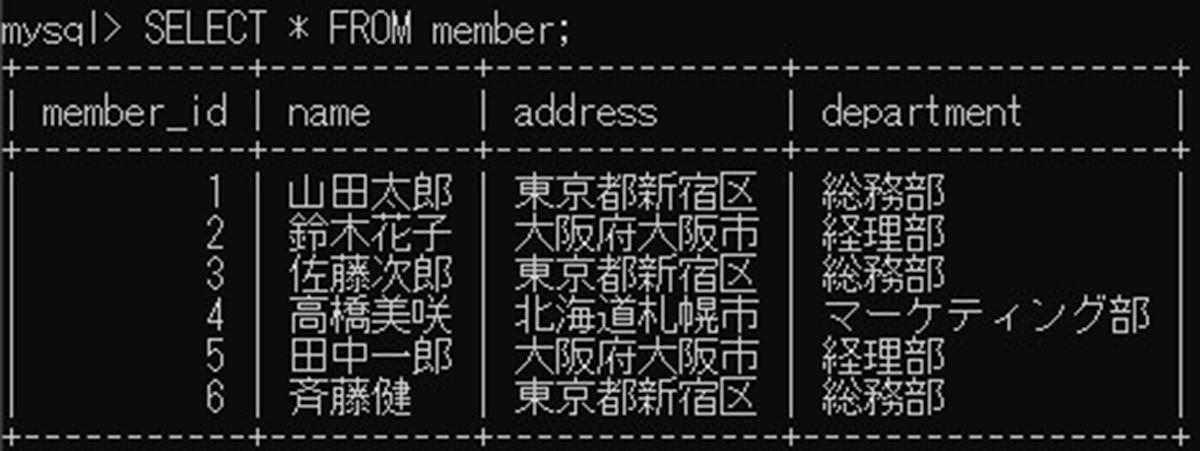
「memberテーブル」のaddressとdepartment列に重複データがあります。
member_id | name | address | department |
1 | 山田太郎 | 東京都新宿区 | 総務部 |
2 | 鈴木花子 | 大阪府大阪市 | 経理部 |
3 | 佐藤次郎 | 東京都新宿区 | 総務部 |
4 | 高橋美咲 | 北海道札幌市 | マーケティング部 |
5 | 田中一郎 | 大阪府大阪市 | 経理部 |
6 | 斉藤健 | 東京都新宿区 | 総務部 |
DISTINCTは複数の列に対して使用できます。複数の列にDISTINCTを適用すると、指定したすべての列の値が一致するデータを除外して出力します。 レコード単位で重複行をまとめる場合は、DISTINCTに指定する列名をカンマで区切って記述しましょう。今回は以下のSQL文を入力します。
SELECT DISTINCT address, department FROM member;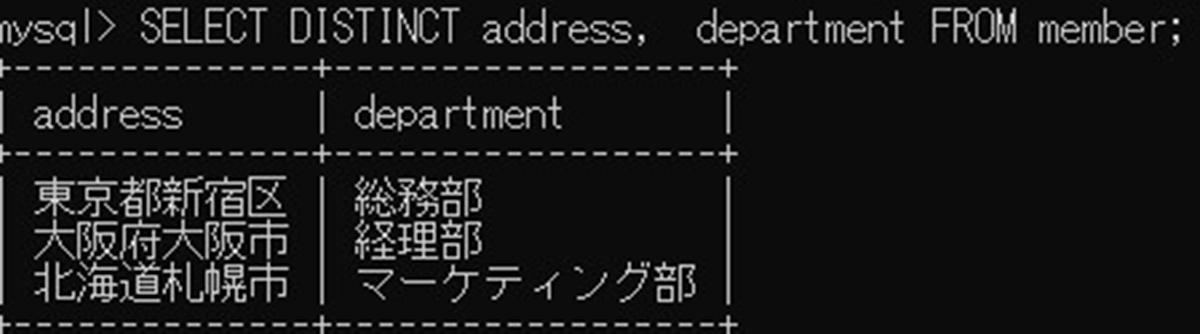
QLのデータ自体を削除するには「DELETE」を使う
SELECTとDISTINCTは、データの重複を取り除く際に使用するコマンドです。一方、データそのものを削除する場合には、DELETEを使用します。
DELETEは、指定されたテーブルを基に、条件に一致するレコードを削除します。条件に該当するレコードが複数存在する場合、それらすべてが削除されます。
また、条件を指定しない場合、テーブル内の全データが削除されます。ただし、全件削除した場合でも、テーブルの構造(スキーマ)はそのまま保持されます。
例えば、以下のようなデータ(itemsテーブル)があります。このデータでは、idが1・3のメロンと2・7のサバが重複しています。
id | name | price | category |
1 | メロン | 100 | 果物 |
2 | サバ | 200 | 魚 |
3 | メロン | 100 | 果物 |
4 | しいたけ | 200 | 野菜 |
5 | マグロ | 300 | 魚 |
6 | ネギ | 200 | 野菜 |
7 | サバ | 200 | 魚 |
8 | タイ | 400 | 魚 |
今回は以下のDELETE文を使って、データを削除します。
DELETE FROM items
WHERE id NOT IN (
SELECT min_id
FROM (
SELECT MIN(id) AS min_id
FROM items
GROUP BY name, price, category
) tmp
);このSQL文は、items テーブルで name, price, category の組み合わせが重複している場合に、id が最小の行を1つだけ残し、それ以外を削除する処理を実行します。このSQL文を実行すると以下のようになります。
id | name | price | category |
1 | メロン | 100 | 果物 |
2 | サバ | 200 | 魚 |
4 | しいたけ | 200 | 野菜 |
5 | マグロ | 300 | 魚 |
6 | ネギ | 200 | 野菜 |
8 | タイ | 400 | 魚 |
idが3のメロンと7のサバのデータが削除されます。また、削除されたデータ分のidは繰り上げされない点に注意が必要です。
SQLでDISTINCTを使う際の注意点
SQLでDISTINCTを使用する際の注意点は、主に以下の通りです。
ここからは、それぞれのSQLでDISTINCTを使う際の注意点について詳しく解説します。
NULLも1つのデータとして扱われる
DISTINCTを使用する際、NULL値も1つのデータとして扱われます。そのため、同じ列に複数のNULLが含まれている場合でも、DISTINCTはそれらを1つにまとめます。
この挙動により、意図しない結果となる場合があります。そのような場合には、DISTINCTを適用する前にWHERE句を使ってNULLを除外することを検討してください。
データ量が多いと速度が低下する恐れがある
大規模なデータセットでDISTINCTを使用すると、クエリの実行速度が低下する可能性がある点には注意が必要です。
特に、大量のデータを含むテーブルや複数の列を対象とする場合、パフォーマンスに影響を及ぼすことがあります。そのような場合は、インデックスを最適化したり、クエリ実行前に余分なレコードを整理したりすることで、システムの応答性を向上させることができます。
活用すべき場面が限定される
すべての列が異なる場合、DISTINCTを使用しても結果は変わらず、処理時間を無駄に消費するだけになります。
そのため、DISTINCTは必要な場面でのみ使用することが重要です。DISTINCTはあくまで「重複を取り除く」という目的に限定して活用するべきです。
DISTINCTとGROUP BYの違い
GROUP BYも重複データを排除する機能を持っています。DISTINCTとは異なる点として、グループ化したデータに対して集計操作を行える点が挙げられます。ここでは、以下の「member_2」テーブルを用いてDISTINCTとGROUP BYの違いについて解説します。
member_id | name | address | department |
1 | 山田太郎 | 東京都新宿区 | 総務部 |
2 | 鈴木花子 | 大阪府大阪市 | 経理部 |
3 | 佐藤次郎 | 東京都新宿区 | マーケティング部 |
4 | 高橋美咲 | 東京都新宿区 | 総務部 |
「member_2」テーブルのaddress列とdepartment列を確認すると、4行目の「東京都新宿区」と「総務部」の組み合わせが1行目と重複しています。そこで、DISTINCTを複数の列に適用するために、以下のSQL文を実行します。
SELECT DISTINCT address, department FROM member_2;この結果、同じaddressとdepartmentの組み合わせが1つだけ出力され、以下のようになりました。
address | department |
東京都新宿区 | 総務部 |
大阪府大阪市 | 経理部 |
東京都新宿区 | マーケティング部 |
一方で、GROUP BYは指定した列の値が同じ行をグループ化し、そのグループに対して集約関数を適用できる点が特徴です。
以下に、「member_2」テーブルでGROUP BYを使用する例を示します。SELECT
address,
department,
COUNT(name) AS row_count
FROM
member_2
GROUP BY
address,
department;このクエリでは、addressと departmentが同じ行をグループ化し、それぞれのグループの行数をrow_countとして表示します。
実行した結果は以下のようになります。
address | department | row_count |
東京都新宿区 | 総務部 | 2 |
大阪府大阪市 | 経理部 | 1 |
東京都新宿区 | マーケティング部 | 1 |
このように、DISTINCTは指定した列の重複を単純に取り除くだけの機能を持っています。
一方で、GROUP BYは列をグループ化し、そのグループに対して集約関数を適用することで、追加の情報を得ることができます(今回の例では、各グループの行数を算出しています)。
この違いにより、GROUP BYはデータの分析や統計処理など、より複雑な用途で利用されることが多いです。
まとめ
今回の記事では、SQLの重複削除方法であるDISTINCTの使い方やDELETEの使い方、DISTINCTを使う際の注意点、GROUP BYの違いなどについて解説しました。SQLのDISTINCTは、SELECT文と組み合わせてデータベースから重複を除外する際に使用するコマンドです。
「SELECT DISTINCT カラム名 FROM テーブル名」の形式で記述し、単一または複数の列に対して適用できます。DISTINCTを使用する際は、NULL値も1つのデータとして扱われることや、大規模なデータセットでは処理速度が低下する可能性があることに注意が必要です。また、GROUP BYもDISTINCTと同様に重複を排除できますが、集計関数との組み合わせが可能な点が異なります。