

「この画像と似た商品を探したい」「過去に見た動画と関連するコンテンツを見つけたい」―このような検索を可能にしているのが「ベクトル検索」です。Google画像検索、Netflix、Spotifyなど、私たちが日常的に使うサービスの多くで、この技術が活用されています。
ベクトル検索とは、データを数値ベクトルに変換し、ベクトル空間での類似度を計算することで情報を検索する技術です。従来のキーワード検索が「文字列の一致」を探すのに対し、ベクトル検索は「意味的な近さ」を数学的に計算します。これにより、テキストだけでなく画像・音声・動画など様々なデータ形式での類似検索が可能になります。
また、ベクトル検索はセマンティック検索やRAG(検索拡張生成)を実現する基盤技術として、AI検索システムに不可欠な役割を果たしています。本記事では、ベクトル検索の仕組みや埋め込み技術、セマンティック検索との関係性、企業での活用方法、導入時のポイントまで、システム開発・データ分析の専門企業である株式会社glorious futureが分かりやすく解説します。
ベクトル検索とは?数値で類似性を見つける技術

ベクトル検索は、テキスト、画像、音声といった様々なデータを「ベクトル」と呼ばれる数値の配列に変換し、ベクトル同士の距離や角度を計算することで、データ間の「意味の近さ」や「類似性」を判断する技術です。これにより、キーワードが完全に一致しなくても、関連性の高い情報を見つけ出すことが可能になります。
ベクトル検索の定義
ベクトル検索の核心は、あらゆるデータを意味的な特徴を捉えた数値のベクトルに変換(ベクトル化・埋め込み)する点にあります。例えば、「犬」「いぬ」「dog」は、文字列としては全く異なりますが、ベクトル検索ではこれらの単語はベクトル空間上で非常に近い位置に配置されます。
このようにデータをベクトル化することで、コンピューターは人間のように「意味」を理解し、文脈に基づいた検索が可能になります。ベクトルとは単純に数値の羅列であり、意味が近いデータほどベクトル空間上で近い位置に配置される仕組みです。
ベクトル検索が注目される背景
ベクトル検索が今、大きな注目を集めている背景には、生成AIとRAG(検索拡張生成)の台頭があります。RAGは、生成AIが回答を生成する際に、外部の信頼できる情報源から関連情報を検索し、それを参考に回答を作成する仕組みです。
この「関連情報を検索する」部分で、ユーザーの質問と意味的に最も関連性の高い文書を高速に見つけ出すために、ベクトル検索が不可欠な役割を果たしています。従来のキーワード検索では見つけられなかった、文脈に沿った情報を的確にAIに提供できるため、生成AIの回答精度を飛躍的に向上させます。
また、ベクトル検索はセマンティック検索(意味検索)を実現する基盤技術でもあり、検索体験の向上に大きく貢献しています。
身近な活用例
実は、私たちはすでにベクトル検索の恩恵を日常的に受けています。スマートフォンの写真アプリで「猫」と検索すると猫が写っている写真が表示されるのも、この技術のおかげです。
サービス名 | 活用例 | ベクトル検索がもたらす価値 |
Google画像検索 | 「夕焼けの海」といった曖昧な言葉で関連画像を検索 | テキストと画像の意味的関連性を捉え、直感的な検索体験を提供 |
YouTube | 視聴した動画に似た内容の関連動画を自動推薦 | ユーザーの興味をベクトル化し、パーソナライズされた体験を創出 |
ECサイト | 閲覧商品に似た商品を「おすすめ」表示 | 商品の特徴をベクトルで比較し、新たな発見や購買機会を促進 |
Spotify | 聴いている曲に似た音楽をプレイリストに追加 | 音楽の特徴をベクトル化し、好みに合った曲を発見 |
このように、ベクトル検索は様々なサービスで活用され、私たちの日常生活をより便利にしています。
ベクトル検索の仕組みと主要技術
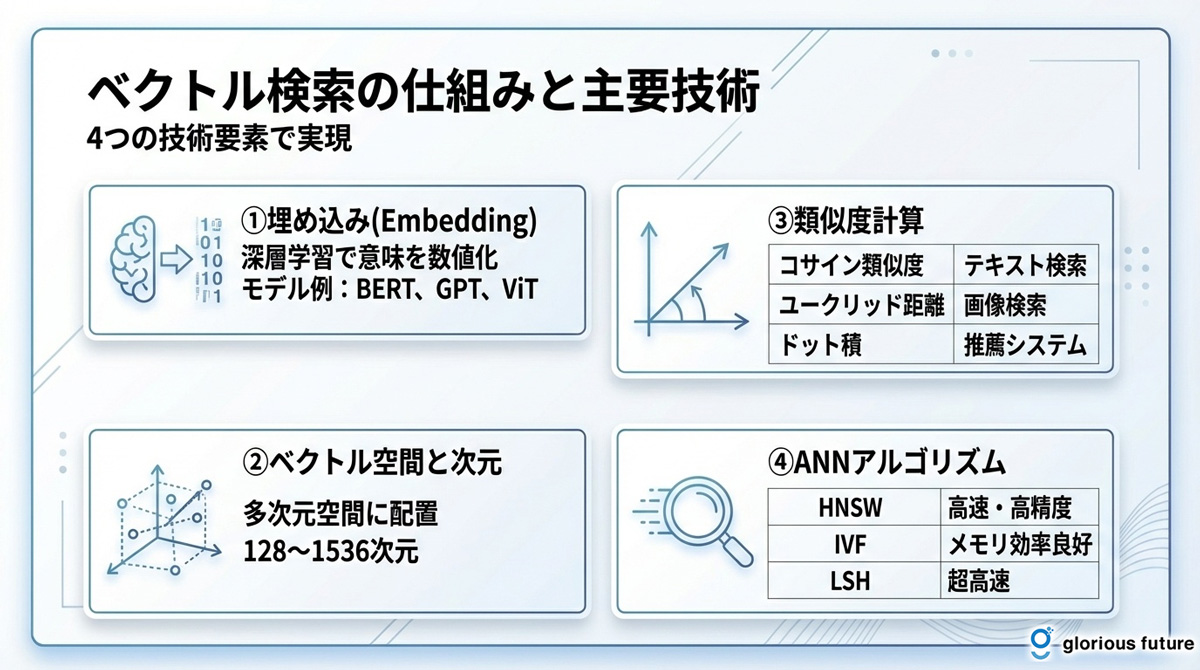
ベクトル検索は、いくつかの重要な技術要素の組み合わせによって成り立っています。ここでは、その仕組みを支える4つの主要技術について解説します。これらの要素を理解することで、ベクトル検索がなぜ高精度で高速な検索を実現できるのかが分かります。
埋め込み(Embedding)によるベクトル化
データをベクトルに変換するプロセスを「埋め込み(Embedding)」と呼びます。このプロセスでは、BERTやTransformerといった深層学習モデルが用いられます。これらのモデルは、大量のテキストや画像データを事前に学習しており、単語や文章がどのような文脈で使われるかを理解しています。
その結果、単なる数値の羅列ではなく、データの「意味」を保持したベクトルを生成できます。例えば、「犬」「ペット」「動物」といった関連する単語は、ベクトル空間上で近い位置に配置されます。
主要な埋め込みモデル:
- テキスト: BERT、GPT、Universal Sentence Encoder
- 画像: ResNet、ViT(Vision Transformer)
- 音声: Wav2Vec、Whisper
ベクトル空間と次元
生成されたベクトルは、「ベクトル空間」と呼ばれる多次元の仮想空間上に配置されます。意味が近いデータほど、この空間上で互いに近い位置にマッピングされます。
ベクトルの次元数は、数百から数千次元にも及ぶことがあり、次元数が高いほどより複雑で微妙な意味の違いを表現できます。ただし、次元数が高すぎると「次元の呪い」と呼ばれる計算コストの増大や精度低下の問題が発生するため、適切な次元数の設定が重要になります。
一般的な次元数:
- 軽量モデル: 128〜384次元(モバイルアプリなど)
- 標準モデル: 512〜768次元(一般的な検索システム)
- 高精度モデル: 1024〜1536次元(高度なAI検索)
コサイン類似度による類似性計算
ベクトル空間上で2つのベクトルがどれだけ似ているかを測る指標として、「コサイン類似度」がよく用いられます。これは、ベクトル間の角度を計算するもので、角度が小さい(=コサイン類似度の値が1に近い)ほど、ベクトルの向きが似ている、つまり意味的に類似していると判断します。
類似度指標 | 特徴 | 主な用途 |
コサイン類似度 | ベクトルの「向き」の類似度を評価。大きさの影響を受けない | テキストの意味的類似度、RAGシステム |
ユークリッド距離 | ベクトル間の「直線距離」を評価。距離が短いほど類似度が高い | 画像特徴量の類似度、クラスタリング |
ドット積(内積) | ベクトルの「向き」と「大きさ」の両方を考慮 | 推薦システム、一部の埋め込みモデル |
コサイン類似度は、ベクトルの大きさに影響されないため、テキストの長さが異なる文書同士を比較する際に特に有効です。
ANN(近似最近傍探索)アルゴリズム
数百万、数千万といった膨大な数のベクトルの中から、クエリに最も近いベクトルを瞬時に見つけ出すには、ANN(Approximate Nearest Neighbor、近似最近傍探索)アルゴリズムが不可欠です。
ANNは、厳密に最も近いベクトルを探すのではなく、非常に高い確率で最も近いであろうベクトルを高速に見つけ出す手法です。これにより、検索速度と精度のバランスを取りながら、大規模データに対応しています。
アルゴリズム | 特徴 | 最適なユースケース |
HNSW | 階層的なグラフ構造で効率的に探索。高精度かつ高速 | リアルタイム性が求められるシステム、高精度な意味検索 |
IVF | データをクラスタに分割して探索範囲を限定。メモリ効率が良い | メモリ制約がある環境、検索速度と精度のバランス |
LSH | ハッシュを用いて類似ベクトルを同じバケットに分類。非常に高速 | 厳密な精度より速度が優先される場合、初期フィルタリング |
現在、最も広く使われているのはHNSW(Hierarchical Navigable Small World)で、多くのベクトルデータベースで採用されています。
ベクトル検索とセマンティック検索の関係性
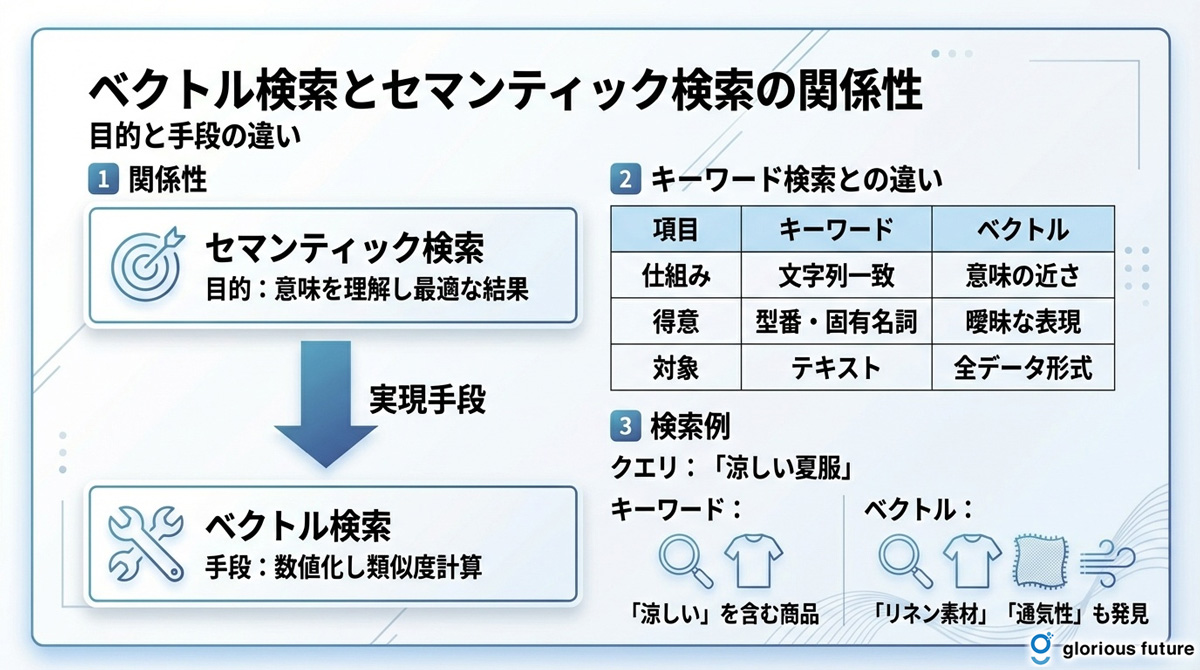
「ベクトル検索」と「セマンティック検索」は、しばしば混同されがちな言葉ですが、両者の関係を正しく理解することが重要です。これらは同じものではなく、「目的」と「手段」の関係にあります。この違いを理解することで、技術選定やシステム設計をより適切に行うことができます。
両者の違い(手段 vs 目的)
両者の関係性は、以下のように整理できます。
セマンティック検索(意味検索) ユーザーの検索クエリの「意図」や「意味」を理解して、最適な結果を返すという目的そのものを指します。「何を達成したいか」という概念です。
ベクトル検索 テキストや画像を意味的なベクトルに変換し、類似度を計算することで、セマンティック検索という目的を実現するための強力な手段の一つです。「どうやって実現するか」という技術です。
つまり、セマンティック検索を実現するためのアプローチは複数考えられますが、現在最も主流で効果的な技術がベクトル検索なのです。
セマンティック検索を実現する技術としてのベクトル検索
ベクトル検索は、単語や文章をその意味に基づいたベクトルとして表現します。これにより、「ノートパソコン」という検索クエリに対して、「PC」「ラップトップ」「モバイルPC」といった、言葉は違えど意味的に関連する情報を含んだ検索結果を返すことができます。
このように、ベクトル検索はデータの表面的な文字列ではなく、その裏にある意味的なつながりを捉えることで、高度なセマンティック検索を実現します。ベクトル検索という技術基盤があるからこそ、セマンティック検索による優れたユーザー体験が可能になるのです。
キーワード検索との3つの違い
ベクトル検索と従来のキーワード検索の違いを理解するために、3つの観点から比較してみましょう。この違いを知ることで、なぜベクトル検索が次世代の検索技術と呼ばれるのかが明確になります。
比較項目 | キーワード検索 | ベクトル検索 |
検索の仕組み | 文字列が完全に一致するか、またはその一部が含まれるか(形態素解析)で判断 | データやクエリを「ベクトル」に変換し、その意味的な近さ(類似度)で判断 |
得意なこと | 型番や製品名、固有名詞など、完全に一致する情報を正確に見つけ出す | 曖昧な表現、同義語、言い換えなど、ユーザーの意図を汲み取った柔軟な検索 |
検索対象 | 主にテキストデータが対象 | テキスト、画像、音声、動画など、ベクトル化できるあらゆるデータ(マルチモーダル) |
具体的な検索例で比較:
検索クエリ:「涼しい夏服」
- キーワード検索: 商品説明に「涼しい」という単語が含まれる商品のみヒット
- ベクトル検索: 「涼しい」という単語がなくても、「リネン素材」「通気性抜群」「メッシュ生地」など、涼しさに関連する特徴を持つ商品もヒット
ベクトル検索のメリット
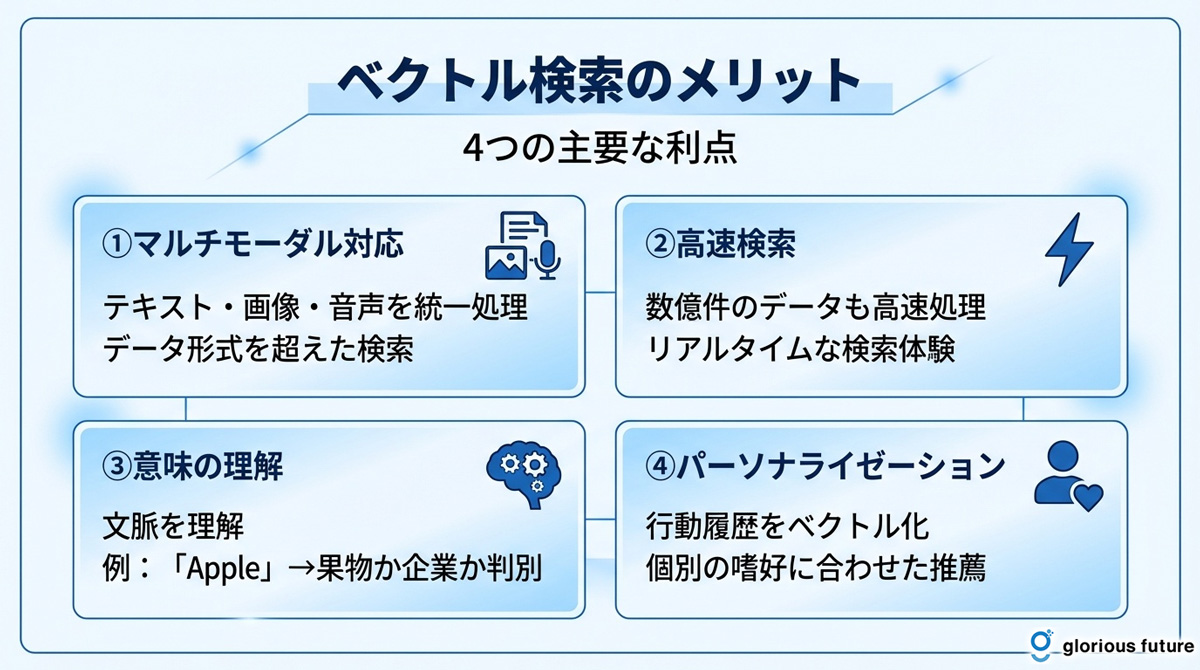
ベクトル検索を導入することで、検索システムは大きな進化を遂げます。
文脈の理解からマルチモーダル対応まで、そのメリットは多岐にわたります。
ここでは、企業がベクトル検索を導入することで得られる主要な利点を4つ紹介します。
マルチモーダル対応(テキスト・画像・音声)
ベクトル検索の最大の強みの一つは、多様なデータ形式を扱える点です。
テキストだけでなく、画像、音声、動画といった非構造化データを統一的に「ベクトル」として扱うことができます。
これにより、例えば「青い空と白い雲」というテキストで画像を検索したり、ある画像に似た雰囲気の音楽を探したりといった、データ形式の垣根を越えた横断的な検索(マルチモーダル検索)が可能になります。
大規模データでの高速検索
前述のANN(近似最近傍探索)アルゴリズムの活用により、ベクトル検索は数百万から数十億といった大規模なデータセットに対しても高速に応答できます。
全てのデータを一つ一つ比較するのではなく、効率的なインデックス構造を用いて探索範囲を絞り込むためです。
これにより、ユーザーを待たせることなく、リアルタイムに近い検索体験を提供することが可能です。
文脈・意味の理解
ベクトル検索は、単語の表面的な意味だけでなく、文章全体の文脈やニュアンスを理解します。
例えば、「Apple」という単語が、文脈によって「果物のリンゴ」を指すのか、「テクノロジー企業のApple」を指すのかを区別できます。
この能力により、ユーザーが本当に求めている情報を提供できる確率が格段に向上します。
パーソナライゼーション
ユーザーの過去の行動履歴(閲覧した商品、クリックした記事など)もベクトル化することができます。
このユーザーベクトルと、アイテム(商品や記事)のベクトルを比較することで、各ユーザーの嗜好に合わせた精度の高い推薦(パーソナライゼーション)が実現します。
これにより、ECサイトでの購買率向上や、メディアサイトでのエンゲージメント向上に貢献します。
ベクトル検索の企業での活用シーン
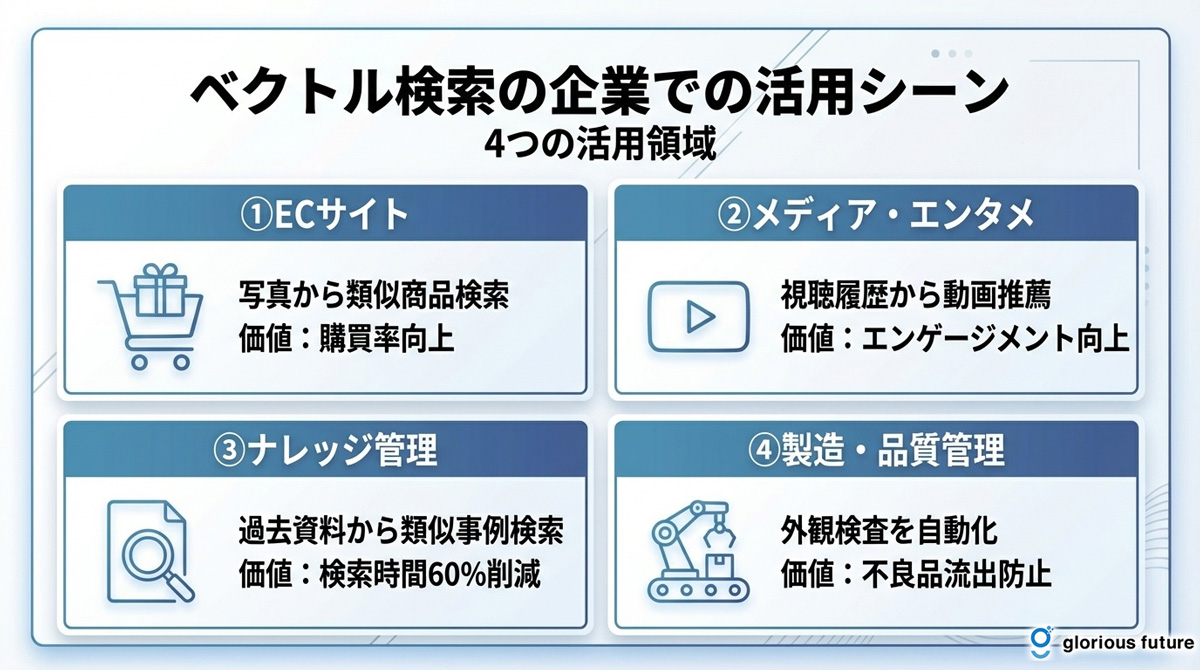
ベクトル検索は、理論上の技術にとどまらず、すでに多くのビジネス現場で具体的な価値を生み出しています。ここでは、特に導入効果が高いと考えられる4つの活用シーンを紹介します。自社のビジネス課題と照らし合わせながら、どのような応用が可能か考えてみましょう。
活用シーン | 具体的なアプリケーション | もたらされるビジネス価値 |
ECサイト | 画像検索、類似商品検索、レビューの意図分析 | ユーザーの直感的な商品探索を支援し、購買転換率を向上 |
メディア・エンタメ | 推薦システム(動画、音楽、記事)、コンテンツ検索 | ユーザーエンゲージメントを高め、滞在時間やリピート率を向上 |
ナレッジマネジメント | 社内文書検索、FAQシステム、RAGによる問い合わせ対応 | 従業員の自己解決率を高め、業務効率化とナレッジ共有を促進 |
製造・品質管理 | 異常検知、類似不具合事例の検索、外観検査 | 製品の品質向上、過去の知見活用による迅速なトラブルシューティング |
活用シーン①:画像検索・類似商品検索
ECサイトで、ユーザーが持っている写真や画像から類似の商品を探せる機能は、ベクトル検索の代表的な活用例です。これにより、商品名が分からない場合でも、ユーザーは目的の商品にたどり着きやすくなります。
具体的な活用例:
- ビジュアル検索: SNSで見かけたファッションアイテムの画像で類似商品を検索
- 類似商品推薦: 閲覧中の商品と似たデザイン・用途の商品を自動表示
- レビュー分析: 「サイズが小さい」「色が写真と違う」など、レビューの意図を理解して改善点を抽出
アパレルサイトで、好みのコーディネート写真から類似の服を探すといった体験は、まさにこの技術によって実現されています。ベクトル検索により、商品発見率が向上し、カート放棄率の低減やコンバージョン率の向上につながります。
活用シーン②:推薦システム(動画・音楽配信)
NetflixやYouTubeのような動画配信サービス、SpotifyやApple Musicなどの音楽配信サービスでは、ユーザーが過去に視聴・視聴したコンテンツの傾向をベクトルで分析します。そして、ベクトル空間上で近い位置にある、ユーザーが好みそうな新しいコンテンツを推薦します。
具体的な活用例:
- 動画配信サービス: 視聴履歴に基づいて好みに合った映画やドラマを推薦
- 音楽配信サービス: 聴いている曲に似た雰囲気の音楽をプレイリストに自動追加
- ニュースアプリ: 読んだ記事の傾向から関連記事を推薦
- ポッドキャスト: 聴いているエピソードに似たテーマの番組を推薦
この精度の高い推薦システムが、ユーザーをサービスに惹きつけ続ける重要な要素となっています。ベクトル検索により、ユーザーエンゲージメントが向上し、サービス継続率やLTV(顧客生涯価値)の向上が期待できます。
活用シーン③:社内文書検索(RAGの基盤)
企業内に蓄積された膨大なマニュアルや議事録、報告書から必要な情報を探し出すのは一苦労です。ベクトル検索を導入すれば、「先月のAプロジェクトの進捗に関する課題」といった自然な文章で検索するだけで、関連性の高い文書を瞬時に見つけ出すことができます。
具体的な活用例:
- 社内ナレッジ検索: 過去のプロジェクト資料や議事録から類似事例を検索
- FAQシステム: 問い合わせ内容の意図を理解し、最適な回答を提示
- RAGシステム: 生成AIと連携し、社内情報に基づいた正確な回答を自動生成
- コンプライアンス対応: 契約書や規定から関連条項を素早く検索
これはRAGシステムの基盤としても機能し、社内情報に特化した高精度なチャットボットの構築にも繋がります。情報検索時間の60〜70%削減や、従業員の自己解決率向上が期待できます。
活用シーン④:異常検知・品質管理
工場の生産ラインで撮影された製品の画像をベクトル化し、正常な製品のベクトル群と比較することで、異常な製品(不良品)を自動で検知できます。正常なパターンから大きく外れたベクトルを持つ製品を異常としてフラグを立てることで、品質管理の自動化と精度向上に貢献します。
具体的な活用例:
- 外観検査の自動化: 製品表面の傷や汚れを自動検知
- 過去の不具合事例検索: 類似した不具合の原因や対策を素早く発見
- 設備の予知保全: センサーデータの異常パターンを検知し、故障を予測
- ネットワーク監視: トラフィックパターンの異常を検知してセキュリティ脅威を発見
ベクトル検索により、検査精度の向上、検査時間の短縮、不良品流出の防止など、品質管理の大幅な改善が可能になります。
ベクトルデータベースとツール比較
ベクトル検索をシステムに実装するには、大量のベクトルデータを効率的に保存し、高速に検索するための専用のデータベース、すなわち「ベクトルデータベース」が必要です。近年、多くのベクトルデータベースや、ベクトル検索機能を統合したツールが登場しています。ここでは、主要な選択肢とその特徴を紹介し、技術選定の参考にします。
主要なベクトルDB
ベクトル検索に特化したデータベースは、パフォーマンスやスケーラビリティに優れています。それぞれに特徴があるため、プロジェクトの要件に合わせて選択することが重要です。
データベース名 | 特徴 | 提供形態 | おすすめ用途 |
Pinecone | フルマネージドのSaaSで導入が容易。高いパフォーマンスと使いやすさが魅力 | SaaS | 商用サービス、迅速な導入が必要な場合 |
Weaviate | オープンソース。GraphQL APIやセマンティック検索機能を標準搭載 | オープンソース/SaaS | カスタマイズ重視、柔軟な検索機能が必要な場合 |
Qdrant | Rust製で高いパフォーマンスとメモリ効率。フィルタリング機能が強力 | オープンソース/SaaS | 高速性重視、複雑なフィルタリングが必要な場合 |
Milvus | 大規模データセットに強く、スケーラビリティが高い。多くのANNインデックスをサポート | オープンソース | エンタープライズ、大規模データ処理 |
Faiss | Facebook AIが開発したライブラリ。データベースではないが、高速な類似性検索エンジンの核となる | オープンソース(ライブラリ) | 研究・プロトタイプ、他システムへの組み込み |
選定のポイント:
- SaaS型(Pinecone等): 運用負荷を最小限にしたい、迅速な導入が必要
- オープンソース型(Weaviate、Qdrant、Milvus): コスト削減、カスタマイズ性、オンプレミス要件
- ライブラリ型(Faiss): 既存システムへの組み込み、完全なコントロールが必要
Elasticsearchなどの統合検索エンジン
すでに多くのシステムで利用されているElasticsearchやOpenSearchといった全文検索エンジンも、近年ベクトル検索機能をサポートするようになりました。これらのツールを利用するメリットは、既存のキーワード検索システムに、ベクトル検索機能を追加する形でハイブリッド検索を比較的容易に実現できる点です。
統合検索エンジンの特徴:
- Elasticsearch: 8.0以降でベクトル検索をネイティブサポート。キーワード検索とベクトル検索のスコアを組み合わせたハイブリッド検索が可能
- OpenSearch: AWSが開発するオープンソース検索エンジン。k-NN(k近傍法)プラグインでベクトル検索に対応
- Apache Solr: 9.0以降でベクトル検索をサポート。既存のSolrユーザーに最適
統合検索エンジンを選ぶべきケース:
- 既にElasticsearchやOpenSearchを利用している
- キーワード検索とベクトル検索を組み合わせたい
- 新たにベクトルデータベースを導入・運用する手間を省きたい
- 全文検索、ログ分析、ベクトル検索を一つのプラットフォームで管理したい
新たにベクトルデータベースを導入・運用する手間を省きたい場合や、既存の検索システムを活かしながらベクトル検索機能を追加したい場合に有力な選択肢となります。
ベクトルデータベースの選定基準
ベクトルデータベースを選定する際は、以下の観点を考慮しましょう。
選定基準 | 確認ポイント |
データ規模 | 数百万件以下→Pinecone、Qdrant / 数千万件以上→Milvus、Elasticsearch |
スケーラビリティ | 将来的なデータ増加に対応できるか、水平スケーリングは可能か |
運用負荷 | SaaS型(運用不要)か、オープンソース型(自社運用)か |
コスト | 初期費用、月額費用、データ量や検索回数による従量課金 |
既存システムとの統合 | 既存の検索エンジンやデータベースとの連携性 |
開発言語・SDK | 使用する開発言語のSDKが提供されているか |
ANNアルゴリズム | HNSW、IVF、LSHなど、要件に合ったアルゴリズムをサポートしているか |
これらの基準を総合的に判断し、自社のビジネス要件に最適なベクトルデータベースを選定することが重要です。
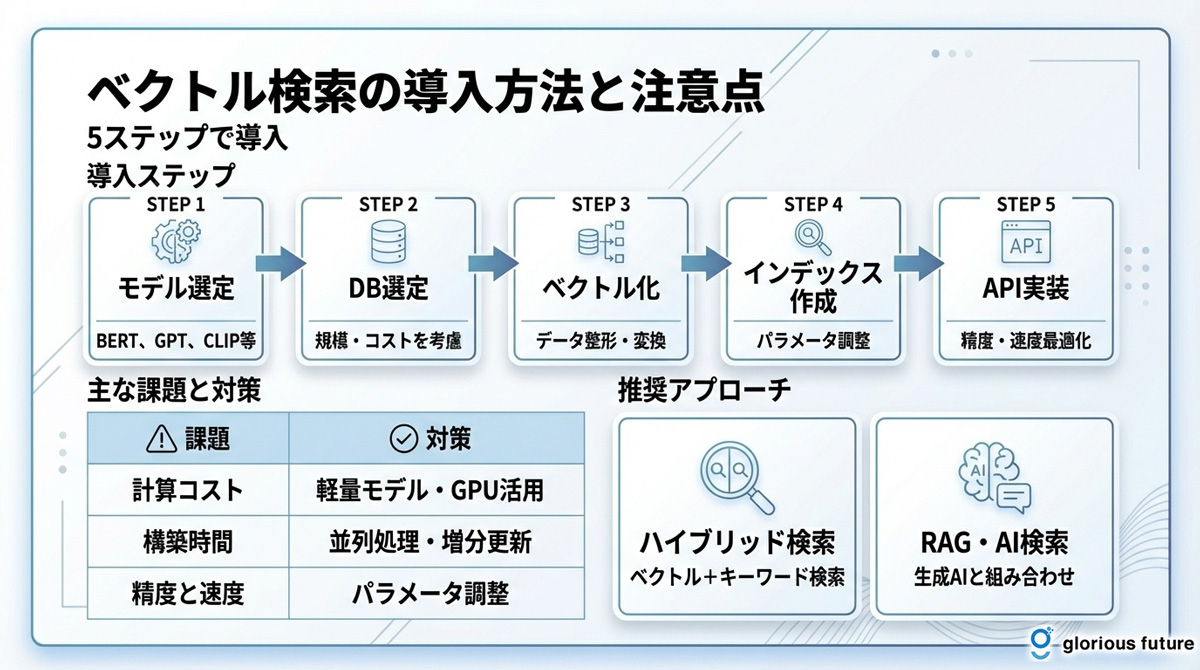
ベクトル検索の導入方法と注意点
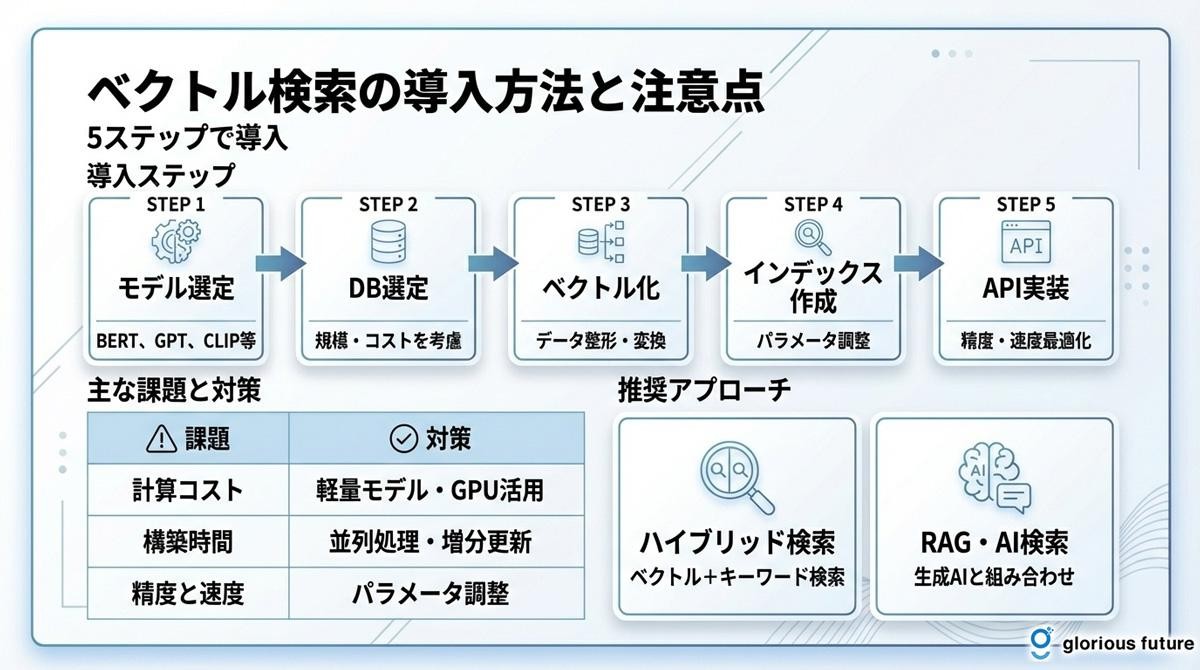
ベクトル検索は強力な技術ですが、その導入にはいくつかのステップと考慮すべき点があります。計画的に進めることで、導入の失敗を避け、その効果を最大限に引き出すことができます。ここでは、基本的な導入ステップと、特に注意すべき課題について解説します。
ベクトル検索の導入ステップ
ベクトル検索の導入は、大きく分けて以下の5つのステップで進められます。
ステップ①:埋め込みモデルの選定 検索対象となるデータ(テキスト、画像など)の特性や、求められる検索精度に応じて、最適な埋め込みモデルを選びます。Hugging Faceなどで公開されている事前学習済みモデルを利用するのが一般的です。
- テキスト向け: BERT、Universal Sentence Encoder、OpenAI Embeddings
- 画像向け: CLIP、ResNet、ViT
- マルチモーダル: CLIP、ImageBind
ステップ②:ベクトルデータベースの選定 前述のツール比較を参考に、データの規模、リアルタイム性の要件、運用コストなどを考慮して、自社のプロジェクトに最適なベクトルデータベースや検索エンジンを選定します。
ステップ③:データの前処理とベクトル化 検索対象となるデータを収集し、適切な形式に整形してベクトル化します。テキストの場合は、文章を適切な長さに分割(チャンク化)することが重要です。
ステップ④:インデックス作成と最適化 ベクトル化したデータをベクトルデータベースに登録し、検索用のインデックスを作成します。ANNアルゴリズムのパラメータを調整し、検索速度と精度のバランスを最適化します。
ステップ⑤:検索APIの実装とチューニング 選定したツールを用いて、検索APIを実装します。期待する検索精度と速度が得られるように、インデックスのパラメータなどを調整(チューニング)する作業も重要です。
導入時の主な課題と対策
ベクトル検索の導入にあたっては、いくつかの課題に直面する可能性があります。
課題 | 詳細 | 対策 |
計算コストが高い | 高品質な埋め込みモデルの利用や、大量のデータのベクトル化には、相応の計算リソース(GPUなど)が必要 | ・軽量モデルの採用(例:MiniLM) ・バッチ処理による効率化 ・クラウドのGPUサービス活用 |
インデックス構築時間 | 大規模なデータセットの場合、ベクトルのインデックス構築に時間がかかる | ・増分更新の実装 ・並列処理の活用 ・オフピーク時間での構築 |
精度と速度のトレードオフ | ANNアルゴリズムのパラメータ設定によって、検索精度と応答速度はトレードオフの関係 | ・用途に応じたパラメータ調整 ・A/Bテストによる最適化 ・ハイブリッド検索の採用 |
ベクトル次元の選択 | 次元数が高いほど精度は上がるが、計算コストも増加 | ・用途に応じた次元数の選定 ・次元削減技術の検討 |
ハイブリッド検索の推奨
ベクトル検索は意味の近さで検索するのに優れていますが、製品の型番や固有名詞のような、文字列が完全に一致する必要がある検索には不向きな場合があります。そのため、多くの実用的なシステムでは、ベクトル検索と従来のキーワード検索を組み合わせた「ハイブリッド検索」が採用されています。
ハイブリッド検索のメリット:
- 網羅性: キーワード検索で厳密な一致、ベクトル検索で意味的な関連性を捉える
- 精度向上: 両者のスコアを組み合わせることで、より関連性の高い結果を上位表示
- 柔軟性: 用途やクエリの種類に応じて、検索手法の重み付けを調整可能
両者の長所を組み合わせることで、より網羅的で精度の高い検索結果を得ることができます。
セマンティック検索・RAGとの組み合わせ
ベクトル検索の真価は、セマンティック検索やRAGといった、より高度なアプリケーションと組み合わせることで発揮されます。
ベクトル検索を基盤とした技術:
- セマンティック検索: ベクトル検索を活用して、ユーザーの意図を理解した検索を実現
- RAG(検索拡張生成): ベクトル検索で関連情報を抽出し、生成AIが正確な回答を作成
- AI検索: ベクトル検索と生成AIを組み合わせた次世代検索
単なる検索機能としてだけでなく、AIが文脈を理解し、より賢く、より信頼性の高い応答を生成するための基盤技術としてベクトル検索を位置づけることが、今後のシステム開発において重要になるでしょう。
ベクトル検索で高速・高精度な情報検索を実現|まとめ

この記事では、ベクトル検索の基本的な概念から、その仕組み、ビジネスでの活用シーン、そして導入にあたっての注意点までを包括的に解説しました。
ベクトル検索は、単なる検索技術のトレンドではなく、AI時代の情報活用を根底から支える重要な基盤技術です。
セマンティック検索を実現する技術としてのベクトル検索
ベクトル検索は、コンピューターが人間のように「意味」を理解するための強力な手段です。
この技術を活用することで、真のセマンティック検索が実現し、ユーザーはより直感的で満足度の高い情報体験を得ることができます。
今後、ベクトル検索の活用はさらに多くの分野に広がっていくことが予想されます。
ベクトル検索を活用したシステム開発は株式会社glorious futureにご相談ください

ベクトル検索技術は、AI検索システムやRAG(検索拡張生成)システムの構築において不可欠な基盤技術です。株式会社glorious futureでは、ベクトル検索とLLM、セマンティック検索を組み合わせた高精度なAI検索ソリューションをご提供しています。
主なサービス内容:
- セマンティック検索とベクトル検索を統合したAI検索システム構築
- RAG技術による高精度な回答生成システムの実装
- 画像検索・推薦システム・社内文書検索など多様なユースケースに対応
- ベクトルデータベースの選定から運用まで一貫サポート
ベクトル検索を活用したシステム開発やAI検索・RAG技術の導入をご検討の企業様は、ぜひお気軽にご相談ください。